ChatGPT 写论文为什么总编假文献?问题不在模型,在你的写作流程
ChatGPT 生成的参考文献格式完美却查无此文?根源不是模型幻觉,而是聊天框写作让引用与正文脱节。本文从工作流角度给出可落地的解决思路。

一个再也熟悉不过的场景:ChatGPT 给的文献,为什么查不到?
你请 ChatGPT 帮忙写一段文献综述,它立刻吐出五条格式完美的参考文献:作者、年份、标题、期刊、卷号页码一应俱全,甚至附上了 DOI。可等你把这条 DOI 粘贴进学术数据库,却提示“未找到匹配记录”。这不是偶然翻车,而是 ChatGPT 辅助学术写作中最高发的问题:参考文献看似规范,实则每一项细节都可能虚构。许多人将这类现象归结为“大模型幻觉”,但真正的问题并不在模型。虚假参考文献的根源,是聊天框写作流程让引用与正文彻底分离——在聊天框生成引用,复制粘贴到 Word,引用就变成孤立文本,与原始出处再无联结。无论事后如何手动核对,成本都极高。

幻觉只是表象:真正的问题出在写作流程
传统学术写作中,无论是使用 EndNote、Zotero 还是手写笔记,研究者总有一个“资料层”来管理文献,写作时从资料库中插入引用,正文和参考文献列表始终关联。可是当写作场景转向 ChatGPT 的聊天框,资料层被自动省略了。你给模型一个指令,它基于训练数据直接生成参考条目,你复制下来,粘贴进 Word。引用和原始出处之间的连接,在粘贴的一刻彻底断裂。日后核对时,你面对的是一行行孤立的文本,没有元数据,没有来源链接,仅凭肉眼和记忆去验证,效率和可靠性都极低。这才是虚假文献成为顽疾的根源,远不止模型输出质量那么简单。
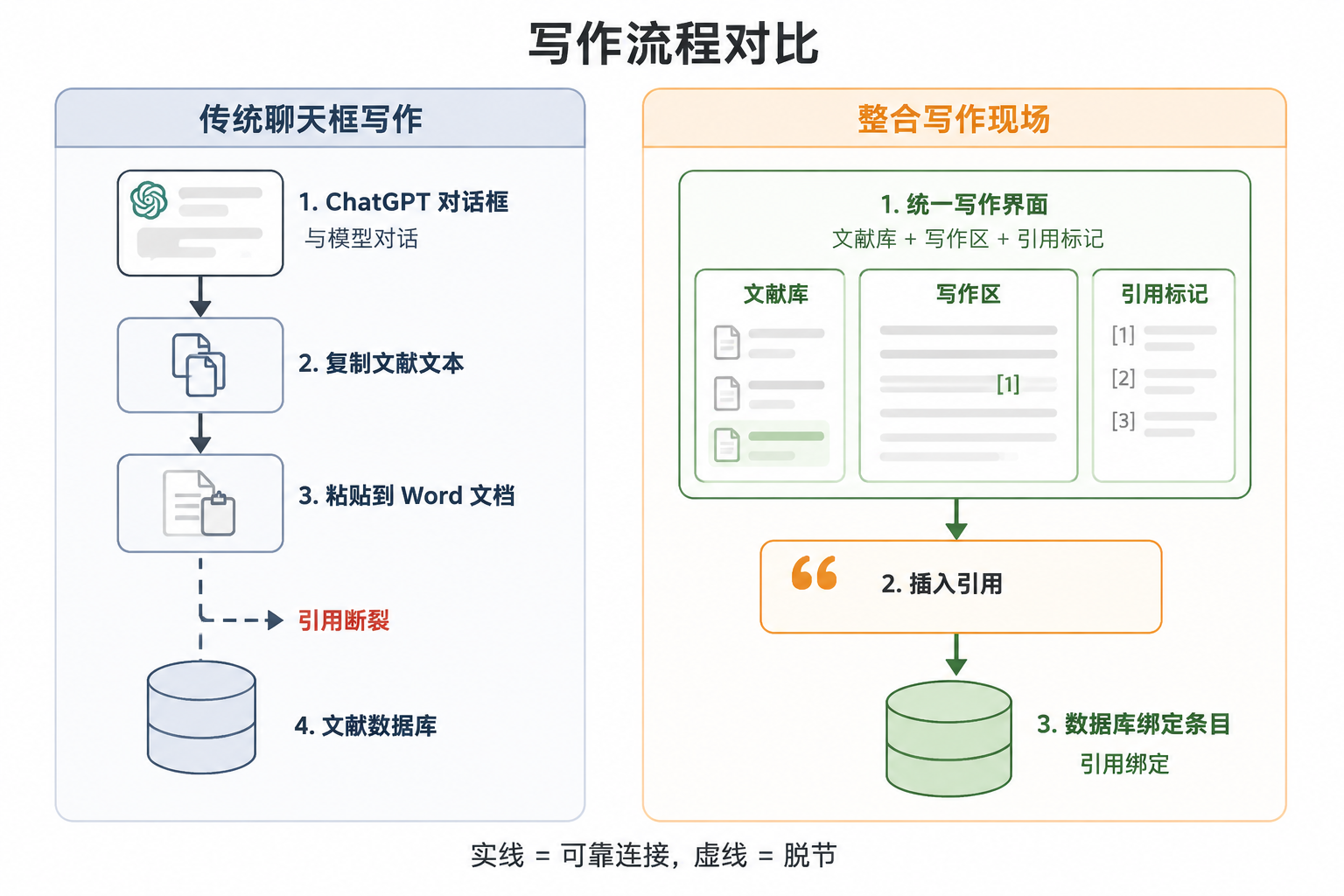
为什么「换一个更准的模型」解决不了根本问题
有人会想,既然 GPT 模型容易编造,那换一个检索增强的、或者训练数据更新更准确的模型是不是就能一劳永逸?坦率地说,即便模型完全基于真实文献库生成,也仍然无法避免参考文献的核对问题。原因很简单:参考文献的真实性不只是“存在”与否,还涉及版本、页码、作者拼写、署名顺序等大量细节,而这些细节可能因为模型输出时上下文压缩或采样随机性而发生错漏。只要生成过程和资料层依然是分离的,你就不得不逐条回溯数据库去一一对账。问题从“验证这条文献是否真实”变成了“验证生成的元数据与数据库条目是否一致”——本质上仍然是同一种对账劳动。工具可以帮忙降低频率,但只要工作流不改变,引用失控的风险就始终存在。
解法:让资料、正文、改稿待在同一个写作现场
既然根源是流程割裂,解法就很清晰:把资料管理、文章生成和后续改稿全都拉进同一个工作现场,让每一次引用都从受控的资料库中产生,并在生成后持续附着在正文中。这意味着,写作不再从空白聊天框开始,而是先构建文献资料层。你通过 DOI、BibTeX 条目或手动录入将文献添加进写作工具,然后在正文中需要引用的位置,从资料库中选择并绑定。此后,无论是 AI 辅助扩写、改写,还是你手动调整,这个引用标记和它背后的元数据始终保持联系,一直带到定稿中。
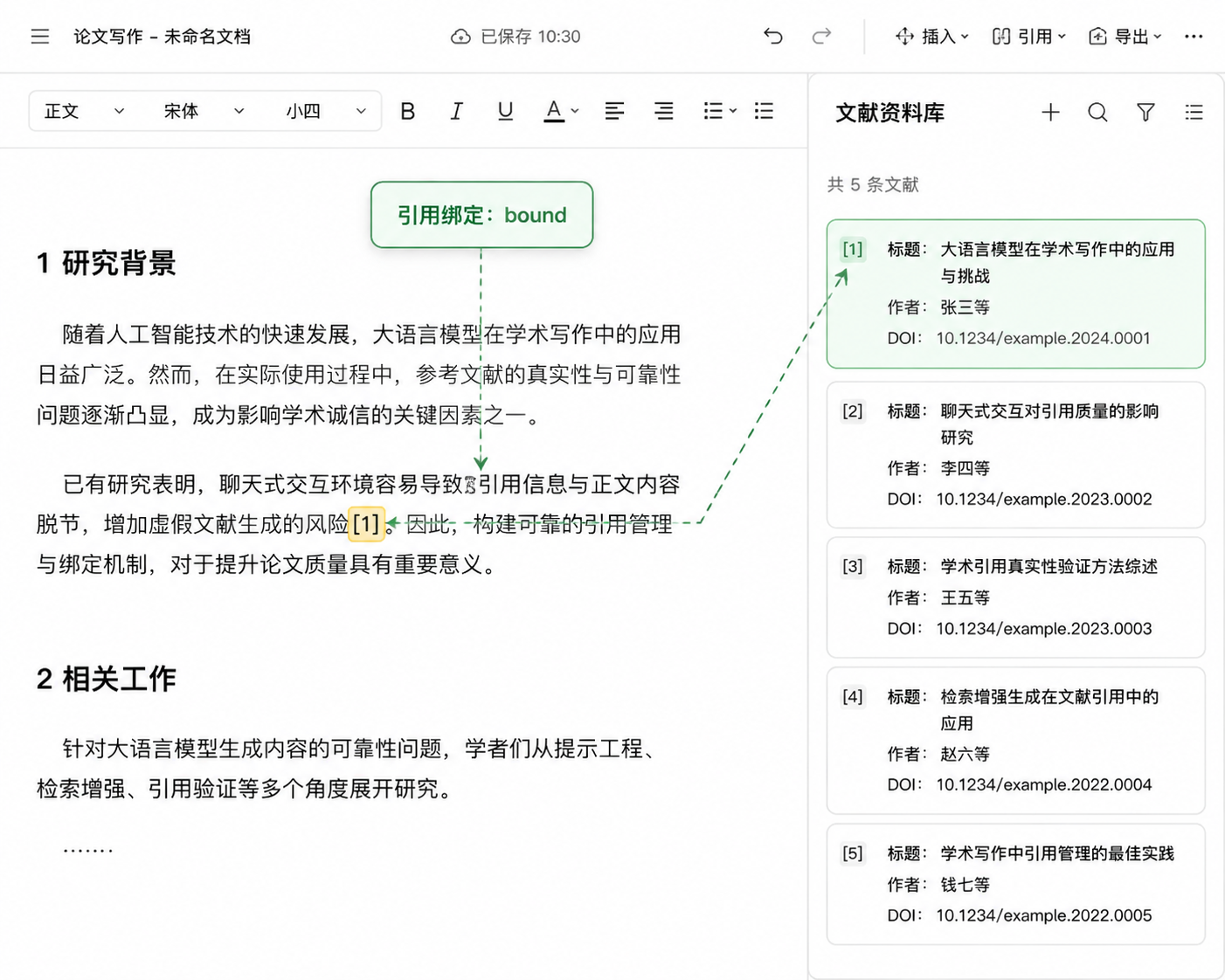
在这样一个流程中,引用不再是写完再补的装饰品,而是写作过程中始终在侧的结构要素。核查也不再是全文写完后的集中苦役,而是分布式地穿插在日常写作和修改中,发现异常的代价小得多。
InkFount 示范:如何用 DOI 绑定与 AI 改稿守住引用底线
以研究型写作工具 InkFount 为例,它按照上述思路,将文献管理、引用绑定和 AI 写作修改整合进一个界面。操作上,你可以直接通过 DOI 或 BibTeX 将文献条目录入,系统会抓取元数据并建立资料库。在写作时,每当你需要引用,就从资料库中选取对应条目,工具会在正文中插入一个绑定标记,并在后台持续维护标记与条目之间的关联。
InkFount 还引入了“三态对账”的引用状态机制:每条被正文引用的文献,其状态会被标记为 bound(已绑定,来源明确)、orphan(正文有引用但资料库中缺失对应文献)或 dangling(资料库中有文献但正文中无引用)。这些状态在写作过程中实时可见,写作者可以随时发现并修复引用缺失或冗余的情况。
AI 改写是另一个容易引入虚假引用的环节。InkFount 的 AI 精确改稿功能在设计上把引用标记当作受保护的结构单元:它会调整表述、优化句子,但不会更改或重新生成引用标记的内容与指向。这样一来,改稿不再是引用失控的新源头,而是与引用保持一致的优化动作。
当然,任何工具都无法保证绝对零虚假文献,你仍然需要做最终的学术判断。但这个过程显著降低了逐条对账的负担,因为大部分异常已经在写作过程中被标记和修正,到达定稿阶段的文献大多已经过显式绑定和层层过滤。
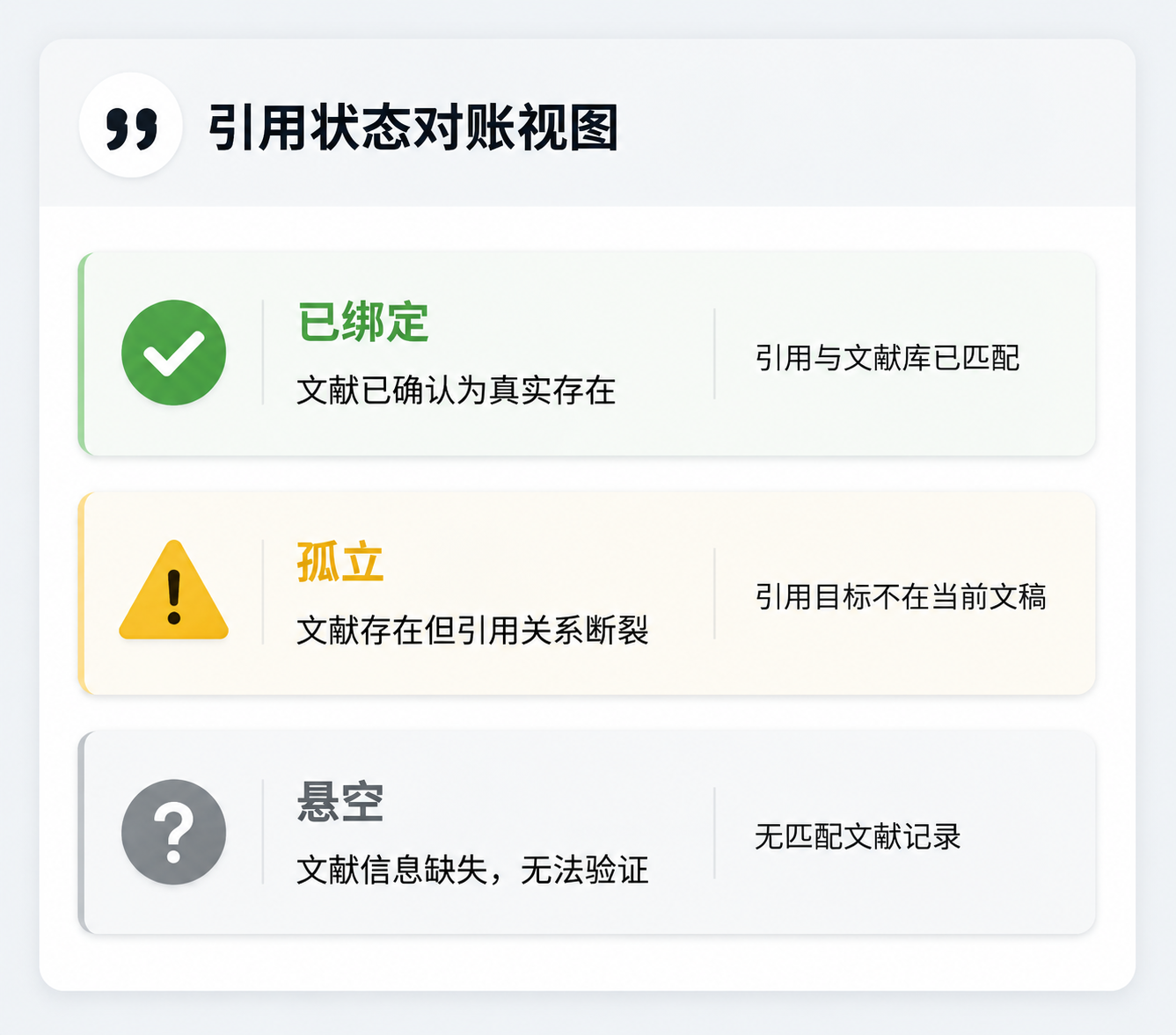
结语:把写作主权留给自己,把引用溯源交给工具
学术写作的核心是审慎的判断与研究者的责任感,这一点是任何模型都无法代劳的。工具的价值在于,它把耗散精力的核对劳动自动化、前移化,让你能把更完整的时间留给真正的思考。当引用生成与绑定、资料层的维护、改稿中的引用保护都由一个连贯的系统默默兜底时,你就不必在每次复制粘贴后提心吊胆地去猜测某条文献是真是假。回到开头的场景,那条查无此文的 DOI,或许本就不该离开它诞生的上下文。守住引用的唯一方式,不是寄望于更聪明的模型,而是自己掌控整条工作流。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
AI 论文改稿工具怎么选:看 diff、引用、导出,而不是看能不能一键生成
市面上的 AI 论文工具都在强调“一键生成”,但严肃学术写作的核心是改稿。本文把工具分成聊天框、一键生成工具、研究型写作工作台三类,用四个硬标准——diff 可见性、撤回能力、引用对账、可交付导出——帮你穿透营销话术,找到真正能用的改稿工具。
Zotero 很强,但为什么论文写到 Word 里还是会乱?——写作阶段的工具断层与补救方案
Zotero 管文献,Word 管正文,AI 管修改——三者之间的断层才是论文写到一半格式崩坏的根源。本文诊断这一隐性问题,并介绍如何用 InkFount 把资料、写作和引用对账统一在一个工作台上,最终干净导出 Word。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。