从宽泛主题到可写问题:AI辅助研究问题生成的系统方法
研究问题的生成不应是一次性的黑盒输出。梳理主题拆解到可行性检验的系统方法,讨论AI的辅助边界,介绍InkFount如何让研究问题的生成在稿件中推进、在文献中锚定、在审阅中收敛。

研究问题的生成不应是一次性的黑盒输出,而应是在稿件上下文中、有文献依据、可逐条审改的可控过程——AI的角色是降低改稿成本,而非替代研究者判断。
一个研究生被告知「围绕数字化转型对中小企业的影响做一篇论文」,或一位行业研究员接到任务「写一份新能源供应链的风险分析报告」——方向有了,怎么把它变成一组能写、能答、能让导师或客户认可的具体问题?这个从主题到研究问题的转化,恰恰是选题阶段最耗心力的一步。缺的不是想法,是一套可重复的拆解逻辑。
主题不会自动变成问题:四个拆解步骤
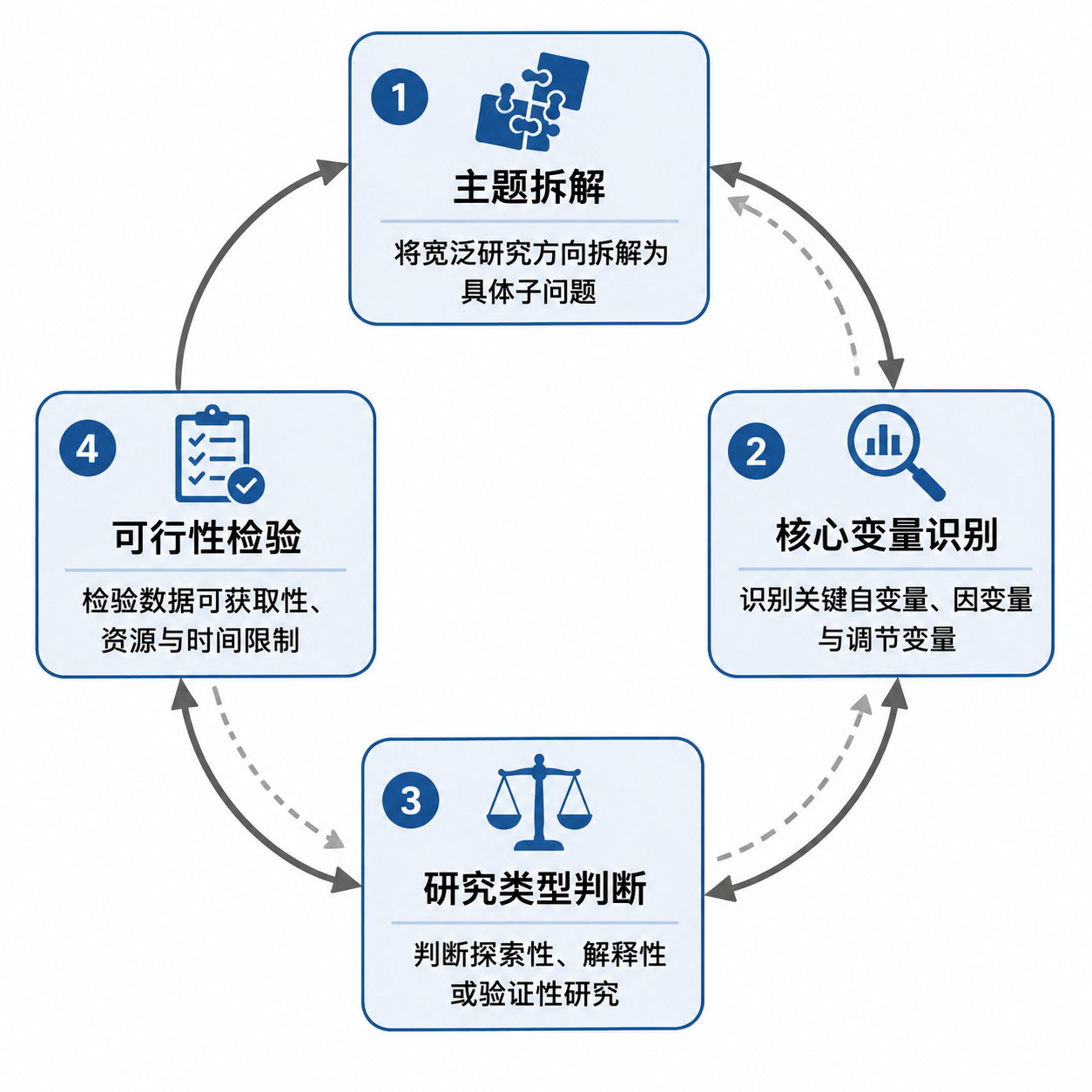
一个宽泛主题落地为可写的研究问题,通常需要走过四步,且四步之间是循环关系——后一步的结果常常倒逼前一步的调整:
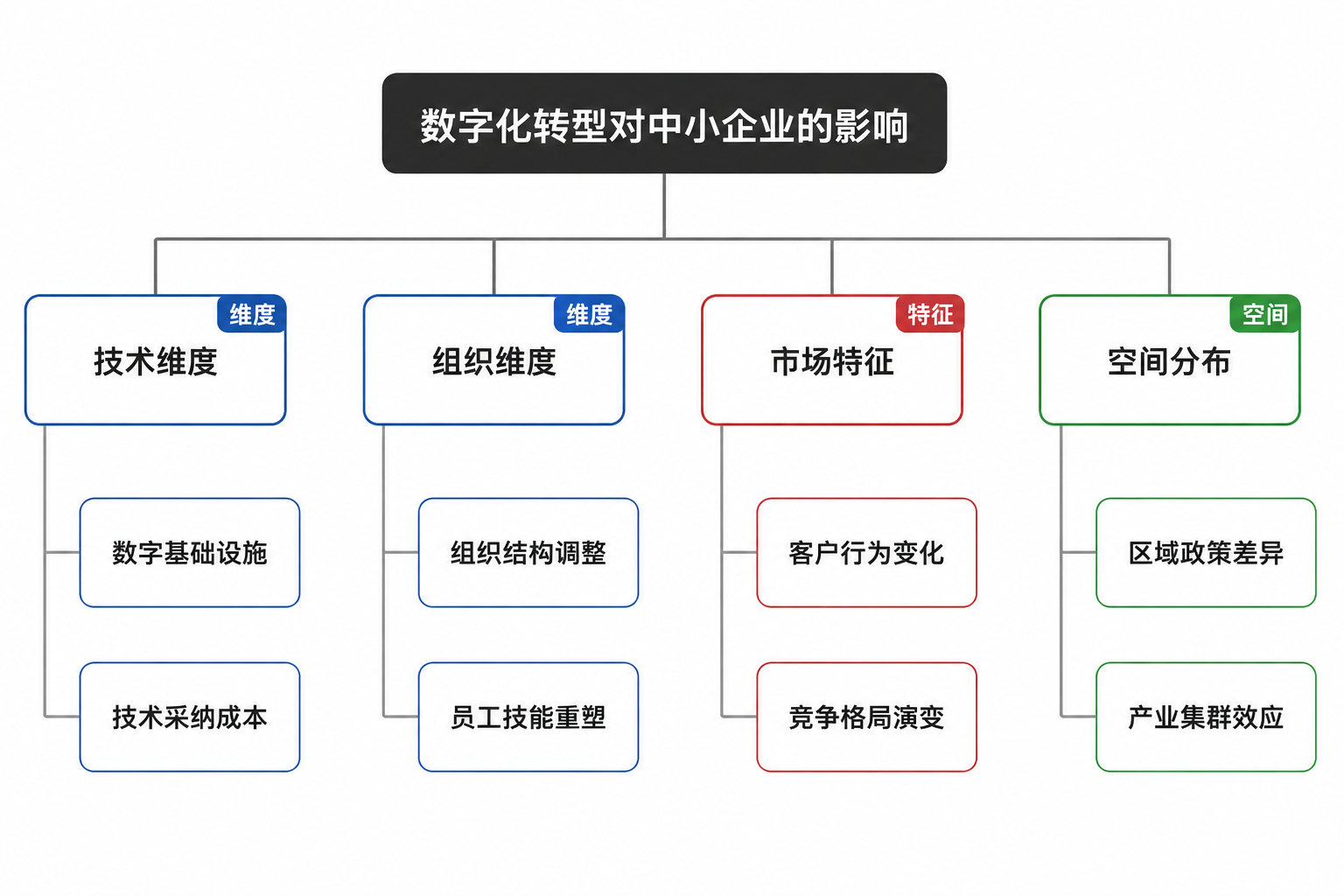
第一步:主题拆解。 将大主题切成可按维度讨论的子议题。以「数字化转型对中小企业的影响」为例:
- 按影响维度拆:组织效率、人力结构、市场竞争力
- 按企业特征拆:制造业与服务业、初创期与成熟期
- 按空间拆:特定区域、特定行业集群
拆到「能用一两句话描述我要研究什么关系」为止。颗粒度过粗,问题仍然空泛;颗粒度过细,后续操作空间被过早锁死。
第二步:核心变量识别。 从子议题中提取要观察或解释的核心变量,并将其操作化:
- 「组织效率」→ 决策速度、部门协同频次、管理成本占比
- 「数字化转型程度」→ IT投入占比、系统覆盖率、数字化岗位比例
变量的可操作性直接决定研究问题能否被经验检验。停留在概念层面讨论,问题写得再漂亮也无法落地。
第三步:研究类型判断。 确认你的问题属于哪一类——探索性(这个现象是什么)、描述性(现象的特征与分布如何)、解释性(什么因素导致了什么结果),还是规范性(应该怎么做)。类型不同,问题的措辞结构和后续研究设计要求完全不同。不少研究写到一半发现方法用错了,根源就在这一步被跳过了。
第四步:可行性检验。 三个硬问题:数据能不能获取?方法会不会操作?范围在给定时间内能不能完成?一个设计精巧但需要三年田野调查的研究问题,对三个月交稿的硕士生就是无效问题。可行性不是妥协,是让问题存活的前提。
AI该站在什么位置:辅助启发,而非黑盒替代
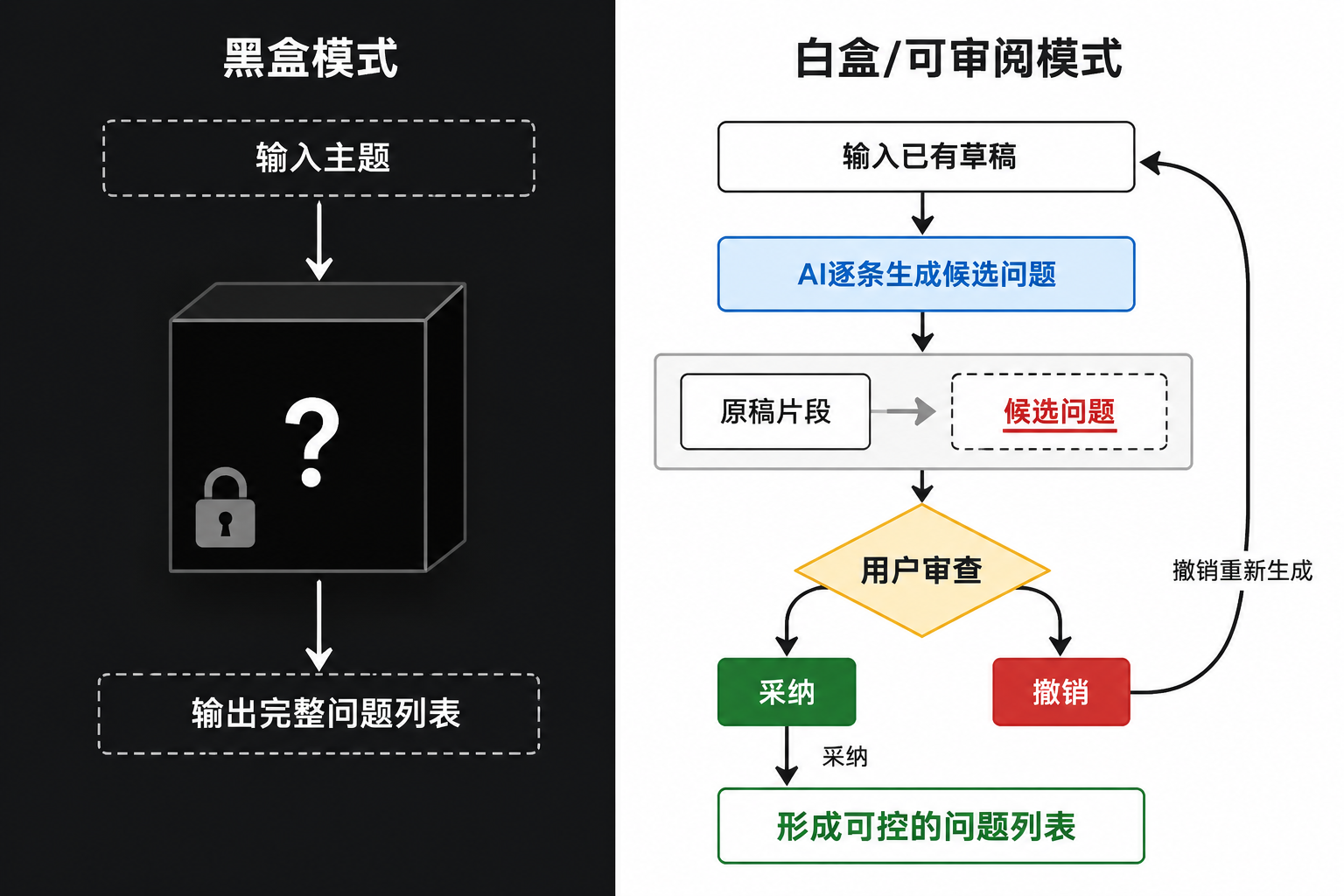
把研究主题丢进ChatGPT,几秒内拿到五六条候选问题——这种做法的问题在于:AI输出的每条问题背后,你不知道它引用了什么文献、基于什么逻辑做出取舍、哪些表述是「推测」出来的。你面对的是一份外观完整但内部不可见的黑盒输出,要么全收,要么重新生成。对于需要放进开题报告或研究计划的问题来说,这种不可追溯性本身就是硬伤。
更合理的角色定位:AI负责降低改稿成本,研究者保留最终判断权。 AI不是替你找到「最佳研究问题」的角色,而是帮你在已有方向基础上快速生成候选表述、逐条审视优劣、反复打磨措辞的那个协作对象。你得看清它每一步改了什么、为什么这么改,然后由你决定采纳、修改还是推翻。
这正是InkFount作为研究型写作工作台的核心思路。
在稿件里打磨问题
多数研究者目前的流程:在ChatGPT或DeepSeek的聊天窗口里来回对话生成研究问题,再把满意的结果复制到Word文档里,手动排版、补充背景、核对引用。这个流程存在一个结构性断裂——研究问题在聊天框中生成,却要在稿件中呈现和论证。复制粘贴不仅耗费时间,更让你在切换窗口的过程中丢失上下文:这段表述为什么这样措辞?AI当时引用了什么依据?之前为什么否决了另一版?
InkFount把研究问题的生成、修改和定稿全部放在Markdown稿件内部完成。你在稿件中写下初步研究方向或已有问题草稿,AI通过读取大纲、定位相关段落、识别上下文,基于稿件已有内容生成或修改研究问题表述,并以diff形式呈现改动。你可以逐条审视每条修改,选择采纳、撤销或让AI重试。整个过程发生在稿件内部,每一处变化都保留审阅权和追溯记录。
这种交互方式的核心是「AI帮你改,你来做决定」。你始终是判断研究问题是否成立、表述是否准确、方向是否值得推进的那个人。
文献核对:研究问题不能悬空
研究问题有一个硬性约束:它必须锚定在真实文献之上。一个看似精巧的问题如果找不到任何文献支撑,要么过于空洞,要么在和空气对话。
聊天框生成研究问题最容易在这里暴露软肋——AI可能在训练数据中混合了不存在的论文标题、虚构的作者年份或失真的研究结论。它可以自信地列出一条看起来合理的文献,而它实际上并不存在。
InkFount的引用核对机制针对的正是这个问题。正文中每个引用标记[@alias]与资料库中的文献元数据绑定,实时显示三态:
- Bound(已绑定):正文引用有明确文献来源,可追溯、可查证
- Orphan(孤立引用):正文标注了引用,但资料库中缺失对应文献——发现空引用
- Dangling(悬空文献):资料库中有文献条目,但正文没有实际引用——发现未使用的资料
![写作界面示意图:侧边栏标注引用状态,绿色已绑定[1],橙色孤儿引用[2],灰色悬空文献,虚线连接正文中对应标记[1][2][?]。](image-04.webp)
在研究问题生成阶段,引用核对的价值在于:当你基于某篇文献提出研究问题时,核对状态会立即告诉你这个问题是否真正站在文献的肩膀上。Orphan状态是一个预警——你引以为据的那篇文献需要补全或核实。Dangling状态则是一个提醒——你收集了某些资料却没有用到,是否忽略了有价值的线索?
这与把参考文献留到交稿前排版的习惯形成根本区别。引用不是格式问题,是写作过程中的来源问题,从研究问题阶段就应该被纳入校验范围。
能交出去,才算写完
研究问题最终要嵌入开题报告、研究计划或论文第一章中交付。如果写完研究问题之后还要手动搬运到另一个文档、重新排版、调整引用格式,整个过程又会回到复制粘贴的循环。
InkFount支持Markdown写作完成后直接导出为Word、PDF或LaTeX格式,引用按GB/T 7714-2015标准格式化,公式渲染和图片题注一并处理。研究问题在稿件中写定、完善、核对,然后整体交付——写作现场就是交付起点。
对于尚在犹豫是否注册的研究者,InkFount的游客模式允许不登录就开始写作,稿件保存在浏览器本地,刷新不丢失。你可以先体验「在稿件中生成和打磨研究问题」的完整流程,再决定是否将其纳入长期工作流。
选择的权利
InkFount接入多个AI供应商——OpenAI、Anthropic、DeepSeek、Moonshot、阿里巴巴等——目的不是堆数量,而是让研究者在中文表达质量、长上下文处理能力、学术语境适配度、使用成本和网络可用性之间拥有选择空间。不同学科、不同写作阶段、不同语种比例,适合的模型可能不同。这个选择权在研究者手上,而不是被绑定在单一模型的能力边界内。
研究问题的质量,归根结底不取决于用了什么AI,而取决于你在这个过程中的判断密度——你在多大程度上审视过每条问题的文献依据、逻辑自洽性和可操作性,在多大程度上把AI的输出当作了对话的起点而非终点。工具的角色是让你每一次判断的成本更低、每一次修改的痕迹可追溯、每一个引用都有据可查。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
学术论文图表格式规范全解:表题、图题与数据来源标注的正确方法
图表格式不规范是论文被退回的高频原因。本文系统讲解表题与图题的位置和编号规则、三线表规范、数据来源的三种标注方法,并从写作流程角度分析如何避免图表返工。
论文引用核对清单:用 bound / orphan / dangling 三态法逐项检查,交稿不返工
一份可直接执行的引用核对清单,掌握 bound / orphan / dangling 三态校验,确保正文引用与参考文献一一对应,符合 GB/T 7714-2015,降低交稿返工风险。
学术论文摘要怎么写?GB/T 6447-2025 新国标下的结构、字数与关键词策略
基于2026年实施的GB/T 6447-2025《文献摘要编写规则》,系统讲解学术论文摘要的结构(目的-方法-结果-结论)、字数规范与关键词选取策略,帮助研究者写出符合期刊要求且检索友好的摘要。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。