当《荷塘月色》被检出62.88% AI率:理解检测误判,从写作过程降低风险
《荷塘月色》《流浪地球》被AI检测工具判为高AI率,揭示了检测技术的底层逻辑。解析误判成因,探讨人控AI改稿如何从写作过程降低误判风险。

2025年5月,《人民日报》、新华网等多家媒体报道了一则引发学术圈热议的测试:朱自清的《荷塘月色》被上传至某主流论文检测系统后,AI生成内容总体疑似度显示为62.88%;刘慈欣《流浪地球》的片段被判为52.88%;唐代王勃的《滕王阁序》更被标注为100%12。这些诞生于AI问世几十年甚至上千年前的文字,在检测工具眼中却成了"AI代写"。
笑话背后藏着一个学术写作者无法回避的现实:如果你正在用AI辅助论文写作,你的稿子也可能被误判。但真正值得追问的,不是"AI率降到多少才安全",而是AI检测误判的根源不在于检测工具本身是否准确,而在于写作过程中人的判断力是否在场。当作者将写作主权让渡给AI一键生成,文本的统计特征便与典型人类写作偏离;而当AI仅作为受控的改稿工具——围绕已有稿件工作、产出可审阅diff、由人逐条裁决——写作过程本身就构成了抵御误判的结构性防护。
AI检测工具到底在检测什么
理解这个判断的前提,是看清检测工具的工作逻辑。当前主流AI检测工具并不"理解"文章内容,而是分析文本的统计特征。两个关键指标构成了判断依据:
困惑度(Perplexity) 衡量文本对语言模型而言有多"出乎意料"。AI生成文本倾向于选择概率最高的下一个词,困惑度偏低——读起来流畅、规整、高度可预测。人类写作则充满跳跃、个人习惯和不那么"最优"的措辞。
突发性(Burstiness) 考察句子结构和长度的变化幅度。人类写作中,长句和短句自然交织,结构参差;AI生成的段落节奏趋于均匀,句子长度和结构变化幅度较小。
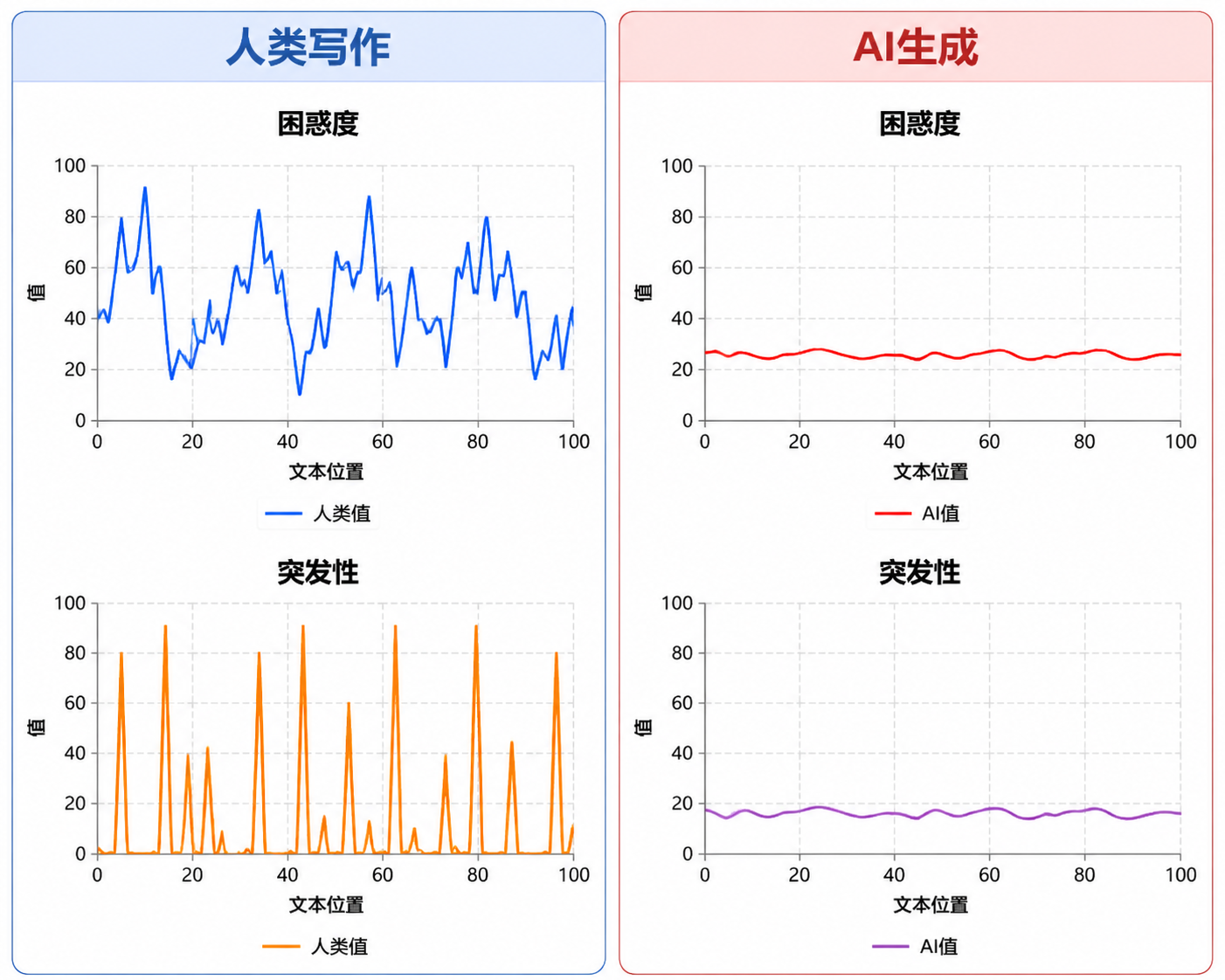
换言之,检测工具做的事,是在统计层面判断一段文本"看起来像不像AI写的"。它不判断事实对错,不评估论证质量,也无法确认文本的真正的作者。
误判并非偶发,而是统计方法的结构性代价
理解了检测原理,误判的成因就清晰了。
非母语写作者的表达一致性。斯坦福大学James Zou团队2023年发表于《Patterns》的研究发现,七款主流AI检测工具对非母语写作者的TOEFL作文平均误判率高达61.22%——超过半数的人类手写文章被错标为AI生成3。非母语写作者在学术语境下反复打磨出的规范表达,在统计上天然趋近"低困惑度、低突发性",这正是检测模型所捕捉的信号。
学术写作的程式化语言。论文的方法部分、实验描述、文献综述大量使用固定句式和领域术语,这些本来就是"可预测性高"的文本。检测工具很难区分"学术规范要求的写法"与"AI生成的写法"。
结构化写作风格。习惯先列提纲、逐段填充、严格控制段落结构的作者,产出的文本在突发性指标上往往偏低——而这恰恰是负责任写作的表现,却被统计模型当作风险信号。
Turnitin在其官方博客中披露的数据显示:对于AI写作内容占比超过20%的文档,其系统的单文档假阳性率低于1%;但句子级别的假阳性率约为4%4。这组数据值得注意的地方在于:厂商公布的假阳性率基于受控测试,而前述斯坦福研究揭示的真实场景中,非母语写作的误判风险远高于平均值。1%的文档级假阳性率放在每年数百万篇论文的基数上,意味着数以万计的学生仍可能被错误标记。
AI一键生成 vs 人控AI改稿:两种模式,两种风险结构
到这里,一个关键区分浮现出来:论文被误判的风险,并不取决于"是否用了AI",而取决于"怎么用的AI"。
当作者将论文主题输入对话框,让AI生成整段甚至整篇内容,文本从构思到措辞都由模型决定。检测工具识别出的低困惑度和低突发性特征并非误判——它们确实反映了文本的生产方式。
另一种使用模式截然不同:作者已有一份稿件——可能是自己写的初稿,或积累数周的研究笔记和论证草稿。AI的角色是围绕已有稿件工作:读取指定段落,理解上下文,针对性地提出修改建议,并将每一次改动以可审阅的差异(diff)形式呈现,由作者逐条决定采纳或撤销。
这两种模式的区别比多数人意识到的更深。前一种模式中,人的判断力退场了;后一种模式中,人的判断力始终站在前台——每一处修改都经过人的审视、取舍和确认。AI降低的是改稿成本,而非替代写作行为本身。
写作主权:从过程中建立结构性防护
这个区分指向一个核心概念——写作主权。
写作主权意味着:作者始终掌握对文本的判断权和最终决定权。AI可以建议换一种表达方式、指出某段论证可以加强、提出结构调整方案,但采纳哪些、拒绝哪些、保留怎样的个人风格,这些决定始终由人做出。
当写作过程本身具备这种主权结构,误判风险就不再是事后需要补救的问题,而是在过程中就被内建化解了。这并不是因为AI改过的句子"看起来更像人写的"——在统计层面,AI润色过的句子可能仍然规整。真正的防护在于:写作过程的透明和可审阅性,本身就是原创性的证据。 如果作者能展示一份清晰的修改记录——哪些段落是自己写的初稿,AI提出了什么建议,作者采纳了哪些、拒绝了哪些——"疑似AI生成"的指控就有了一条可供验证的防线。

逐条采纳/撤销的diff记录之所以能作为结构性申诉证据,原因在于这种日志难以事后伪造——它记录了修改前后文本的精确对应关系、每一次决策的时间序列以及AI建议与人类最终选择之间的分歧。当审阅者质疑某段文字"是否由AI生成"时,作者拿出的不是一句解释,而是一条从初稿出发、经AI建议、由人裁决的完整过程链。
这也是InkFount这类研究型写作工作台的设计逻辑:AI不是独立生成内容的"作者",而是围绕作者已有稿件工作的改稿工具。AI读取指定段落、产出可逐条审阅的diff、每一次修改保留采纳/撤销记录——这些机制不是用来"降低AI检测率"的,而是确保写作过程可追溯、可审查、可交付。与此配套,正文引用与资料库的绑定校验(每一处引注是否对应真实来源、每一条资料是否被正文使用),也从另一个维度为作品的独立性提供了支撑。
几点可以落地的方向
不把降低AI检测率当作目标,而是让写作过程本身可解释——这或许是面对误判风险时更扎实的思路:
- 保持初稿的"人味"。AI更适合在你已有内容的基础上改稿,而不是替你从零开始。先写出自己的论证框架和核心段落,哪怕粗糙,它承载了你的思维路径和表达习惯。
- 审阅而非盲从。对AI的每一条修改建议保持判断。如果AI建议的措辞偏离了你想表达的意思,就撤销;如果觉得自己的原句虽然不那么"流畅"但更准确,就保留。
- 保留过程痕迹。选择能留下修改记录的工具——草稿版本、AI修改的diff记录、逐条采纳或撤销的日志。这些不是负担,而是在需要时证明写作过程独立性的材料。
- 把引用当作写作的一部分,而非导出前的格式任务。写作过程中就完成引用与来源的绑定,让正文每一处引注都有对应的真实资料。论文不只在"查重率"上过关,在论证根基上也经得起追问。
结语
《荷塘月色》被标为62.88%的AI率,与其说是检测工具闹了笑话,不如说它揭示了一个事实:用统计特征判断文本的"人类性",天然地会将某些人类的写作风格误判为机器所为。
严肃的学术写作,本质上是可控、可审、有来源、能交付的。当写作过程本身承载着作者的判断、取舍和来源依据,"被误判"就不再是一个悬在头顶的黑箱威胁,而是一个可以被过程化解的问题。
Footnotes
-
《当〈荷塘月色〉被判为AI生成……》,《人民日报》2025年5月23日,http://paper.people.com.cn/fcyym/pc/content/202505/23/content_30077387.html ↩
-
《〈滕王阁序〉AI率100%?别让"唯技术"伤了真原创》,新华网2025年5月12日,http://www.news.cn/comments/20250512/24c40e4505fe439f913c37cf253807c4/c.html ↩
-
Liang, W., et al. "GPT detectors are biased against non-native English writers." Patterns (2023). https://doi.org/10.1016/j.patter.2023.100779 ↩
-
Turnitin. "Understanding AI writing detection: False positive rates." Turnitin Blog. https://www.turnitin.com/blog/understanding-the-false-positive-rate-for-sentences-of-our-ai-writing-detection-capability ↩
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
AI 论文改稿工具怎么选:看 diff、引用、导出,而不是看能不能一键生成
市面上的 AI 论文工具都在强调“一键生成”,但严肃学术写作的核心是改稿。本文把工具分成聊天框、一键生成工具、研究型写作工作台三类,用四个硬标准——diff 可见性、撤回能力、引用对账、可交付导出——帮你穿透营销话术,找到真正能用的改稿工具。
ChatGPT 写论文为什么总编假文献?问题不在模型,在你的写作流程
ChatGPT 生成的参考文献格式完美却查无此文?根源不是模型幻觉,而是聊天框写作让引用与正文脱节。本文从工作流角度给出可落地的解决思路。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。