AI论文方法部分写作指南:把研究设计讲清楚,而不是把步骤列出来
方法部分的核心不是罗列步骤,而是构建一条可复现、可追溯的研究设计逻辑链。本文拆解方法部分的写作结构、常见陷阱,并介绍如何借助AI精确改稿与引用核对机制,在保持写作主权的前提下完成方法部分撰写。
方法部分的核心不是罗列步骤,而是构建一条可复现、可审阅、可追溯的研究设计逻辑链。在AI工具涌入学术写作的当下,这条链不应交给AI黑盒生成,而应以「写作主权」为原则——作者保留每一步的判断权,AI通过精确patch改稿、引用核对和过程透明成为可审计的协作伙伴,最终经由Markdown到Word/PDF/LaTeX的交付链完成从思路到提交的无缝衔接。
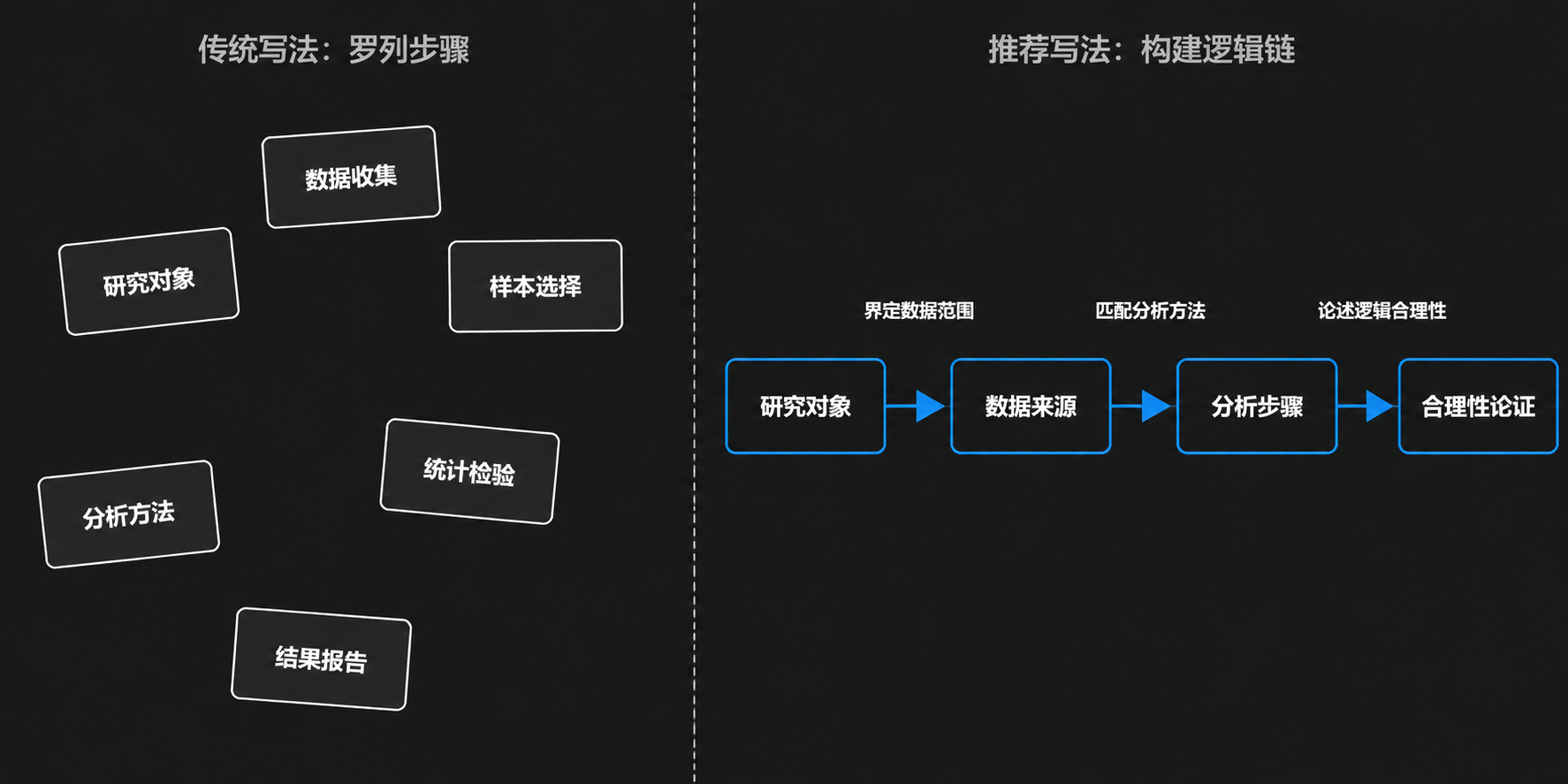
写过论文的人都知道,方法部分最容易写,也最难写好。说它容易,是因为你确实做了这些事——收数据、选样本、跑分析,照实写下来似乎不费力气。说它难,是因为审稿人退回的意见里,关于方法的质疑往往最致命:「样本选取依据是什么?」「这个分析步骤为何跳过中间变量?」「描述太过笼统,无法复现。」问题的根源就在于:很多人把方法部分写成了操作清单,而不是一条逻辑链。
方法部分写的不是「做了什么」,而是「为什么这样研究是成立的」
方法部分承担着一个被反复低估的功能:让读者——尤其是审稿人——相信你的研究设计是站得住脚的。这不仅仅需要交代研究对象是谁、数据从哪来、用了什么分析方法,更需要把这些环节之间的因果关系讲通。
一条完整的方法逻辑链通常包含四个节点:
研究对象 → 数据来源 → 分析步骤 → 合理性论证
这四个节点之间不是并列关系,而是递进与支撑关系。研究对象决定了你需要什么样的数据;数据的性质决定了分析工具的选择;而合理性论证贯穿始终,解释每一步选择为何适用、边界在哪里、排除了哪些替代方案。
举例来说,一个管理学研究中,你选择某企业中层管理者作为研究对象,这一选择本身就隐含了对样本可达性、岗位典型性和研究问题匹配度的判断。如果你只写「本研究的调查对象为某企业中层管理者」,而不解释为何这个群体能回答你提出的研究问题,也不说明样本量与统计检验力的关系,审稿人就无法判断你的结论在什么范围内有效。
方法部分的三个常见硬伤
第一,描述笼统,不可复现。 「采用问卷调查法收集数据」——什么问卷?条目从哪来?信效度如何?发放多少份、回收率多少?这些信息如果缺失,同行无法重复你的研究。可复现性不是一句口号,它要求你的方法部分写得足够具体,具体到另一个研究者读完后,能沿着相同的路径完成一次独立检验。
第二,逻辑跳跃,审稿人看不懂因果链。 常见的是从数据来源直接跳到分析结果,中间缺少分析策略的选择依据。比如用了回归分析,却没有说明为何选择这一模型而非其他模型,也没有交代变量处理方式(标准化、取对数、虚拟变量设置)。审稿人不是你的导师,不会帮你脑补缺失的推理环节。
第三,引用来源标注不清或遗漏。 方法部分大量依赖前人的方法论依据——量表出处、分析方法引用、抽样策略参考文献。正文中提到了某个方法,参考文献列表里找不到;或者参考文献列了,正文中看不出对应关系。这种脱节在审稿中非常刺眼,轻则要求补充,重则引发对学术规范的质疑。
![学术论文方法部分特写,三处红色手写批注:“样本量如何确定?”“引用[23]未在参考文献中找到”“此步骤与前一步逻辑不衔接”,暖黄色纸张背景。](image-02.webp)
AI参与方法部分写作:问题不在「能不能用」,而在「怎么用」
目前关于AI学术写作的讨论容易走向两个极端:一端是「一键生成论文」的效率叙事,另一端是「AI写作等于学术不端」的伦理恐慌。两种声音都回避了一个更实际的问题——研究者需要的是一个能降低改稿成本、同时不剥夺判断权的工具。
方法部分的写作尤其不适合「一键生成」。研究设计的细节、每一步选择的理由、数据的特殊性,这些只有作者自己清楚。黑盒生成几段看似通顺的文字,表面上省了时间,实际上埋下了逻辑断裂和事实错误的隐患。更麻烦的是,生成的内容难以追溯修改来源——你不知道AI从哪里改起、改了什么、依据是什么。
更务实的思路是:把AI定位为一个能够精确读取已有稿件、在指定位置执行修改、并将每一次修改以可审阅方式呈现的协作工具。作者写完初稿,AI基于稿件内容进行结构调整、局部改写、逻辑梳理,每次修改以diff形式交付,作者逐条判断采纳、撤销还是重试。写作的判断权始终在作者手里,AI负责降低执行成本。
这正是InkFount所采用的「精确patch改稿」机制。它不是让AI生成一整段方法部分,而是让AI围绕你已有的稿件工作——读取结构提纲、定位具体段落、检索相关文本,然后针对性地改写、调整或补充。产出的不是一块黑盒文字,而是一条条可独立审阅的修改建议,你可以逐条采纳、撤销或重试。
方法部分的引用,应该在写作中完成核对,而不是导出前才格式化
另一个容易被忽视的问题是引用管理。多数人的习惯是:写作时随手标注一个编号,等全文写完再用Zotero或EndNote统一格式化。这套流程的盲区在于——写作过程中你无法实时知道:正文标注的文献是否都存在于资料库中?资料库中的文献是否都被正文引用过?某个引用标记后是否遗漏了来源信息?
这些问题如果在写作阶段积累下来,到格式化和审稿阶段就会变成需要逐条排查的体力活。
InkFount的引用核对机制尝试从源头解决这个问题。正文中以 [@alias] 形式标记引用,每条标记与资料库中的条目绑定。系统提供三种状态校验:bound(正文标记与资料库条目已绑定,状态正常)、orphan(正文有引用标记但资料库中找不到对应条目)、dangling(资料库中有条目但正文未引用)。写作过程中随时可以扫一眼状态分布,发现问题当场修正。
![引用核对面板示意图,左侧正文高亮[@Smith2024]等引用标签,右侧以绿/橙/灰三色状态标签展示bound/orphan/dangling校验状态](image-03.webp)
这本质上把引用的管理从「导出前集中格式化」前移到了「写作中持续校验」。引用不只是参考文献列表的格式问题,它首先是正文论断与方法论来源之间的可追溯关系。方法部分每一句涉及前人方法的陈述,都应该对应一个可查的来源——这个要求在手动写作中很难严格执行,但有了实时核对,就变成了一件看得见的事。
从思路到提交:方法部分的完整交付链
方法部分最终要提交——可能是Word文档交给导师,可能是PDF上传期刊系统,也可能是LaTeX源码嵌入学位论文模板。不同格式之间的转换往往带来额外的返工:Markdown写的内容贴到Word里格式错乱,参考文献编号对不上,公式渲染异常。
一个面向研究型写作的工作台,在交付侧的价值在于让作者在一个环境中完成从写作到导出的闭环。InkFount以Markdown为主入口——对大多数社科、管理、法学、医学研究者而言,Markdown的学习成本远低于LaTeX,同时又比Word更适合结构化长文的控制。完成方法部分写作后,可以直接导出为Word文档(符合中文排版习惯)、PDF或LaTeX源码,参考文献按GB/T 7714-2015标准自动格式化。
这省去的不是某个单一环节的时间,而是跨工具、跨格式反复调整的隐性成本。
多模型选择对中文研究型写作意味着什么
方法部分的语言有自身特点:术语密度高、逻辑连接词多、中英混杂场景频繁。不同AI模型在中文表达质量、长上下文处理能力、学术语境的适配度上差异显著。有的模型英文处理能力强但中文长句容易失控,有的模型中文表达流畅但对学术术语的调用不够精准,还有的在处理较长方法部分时上下文窗口不足导致修改前后不一致。
多模型支持的实际意义不在于「模型越多越好」,而在于作者可以根据稿件的具体需求选择最匹配的模型。中文表达要求高时选用中文能力强的供应商,方法部分篇幅长时选择上下文窗口大的模型,预算有限时在成本和效果之间做权衡。这种选择权,本身就是写作主权的一个组成部分。
方法部分写作的底层原则
回过头来看,方法部分的写作困境和方法本身的特性是绑在一起的。方法要求精确,写作容易模糊;方法讲究逻辑递进,写作容易跳跃;方法依赖前人依据,写作容易遗漏来源。
AI工具的介入,不改变方法部分「谁来写」这个根本问题——作者始终是那个做研究的人,也只能由作者来判断每一步设计的合理性。但AI可以改变的是「写的过程多费力」:把机械的改稿、格式调整、引用排查从作者的认知负荷中剥离出去,让作者把精力集中在判断上——判断逻辑链是否通顺,判断每一步选择的合理性是否得到了充分论证,判断每一处引用是否经得起追溯。
把研究设计讲清楚,这件事永远属于研究者自己。工具的作用,是让这件事做得不那么累,同时不丢掉你应该保留的东西:对每一个字的判断权,对每一个来源的可追溯性,以及对自己研究设计的完整掌控。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
学术论文图表格式规范全解:表题、图题与数据来源标注的正确方法
图表格式不规范是论文被退回的高频原因。本文系统讲解表题与图题的位置和编号规则、三线表规范、数据来源的三种标注方法,并从写作流程角度分析如何避免图表返工。
论文引用核对清单:用 bound / orphan / dangling 三态法逐项检查,交稿不返工
一份可直接执行的引用核对清单,掌握 bound / orphan / dangling 三态校验,确保正文引用与参考文献一一对应,符合 GB/T 7714-2015,降低交稿返工风险。
学术论文摘要怎么写?GB/T 6447-2025 新国标下的结构、字数与关键词策略
基于2026年实施的GB/T 6447-2025《文献摘要编写规则》,系统讲解学术论文摘要的结构(目的-方法-结果-结论)、字数规范与关键词选取策略,帮助研究者写出符合期刊要求且检索友好的摘要。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。