当你把论文全文丢给 AI:为什么逐段修改才是研究者的正解
全文丢给 AI 润色,结构走样、论证被换、引用丢失——这些失控场景正在消耗研究者的信任。逐段修改把判断权交还作者,用可审阅的精确补丁替代黑盒生成。

把一篇两万字的论文全文粘贴进 ChatGPT 对话框,等它吐出「润色版」——这个动作在研究生群体里越来越普遍,但翻车也在同步发生。导师反问:这里为什么删掉了反例?那段文献评述怎么变成了对已有研究的复述?引用标记去哪儿了?
这不是 AI 不够聪明,是全文重写这个操作本身就押错了注。
全文重写的四重失控
把整篇稿件交给通用 AI 做一次性的语言润色或结构调整,失控往往以四种方式出现,且它们互为连锁。
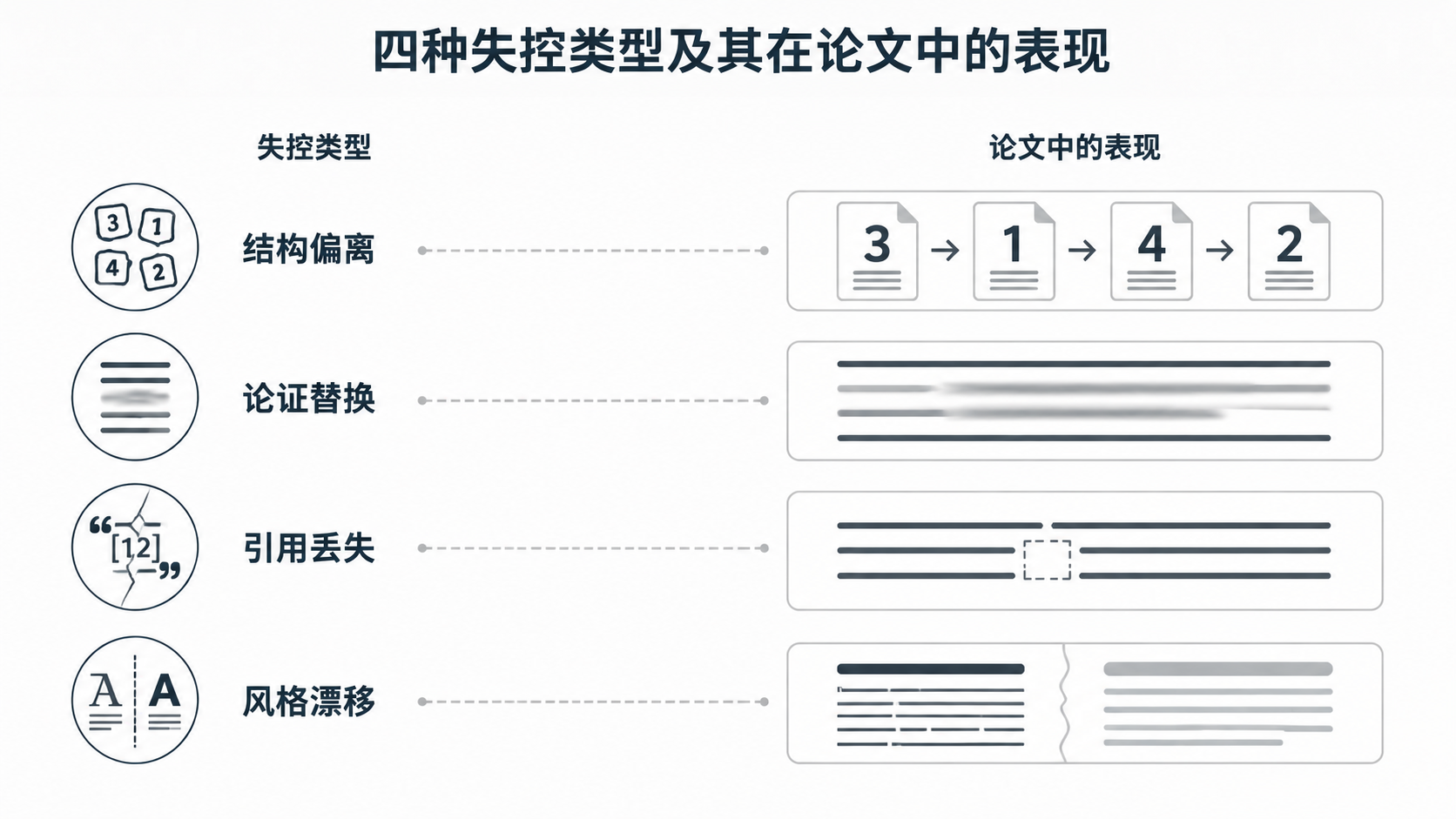
结构偏离。 AI 对长文的全局结构理解依赖于其上下文窗口内的信息分布。当论文包含多层级的章节嵌套、理论推演和实证分析时,模型倾向于按照自己推断的「理想论文结构」重新排布内容,而非尊重作者已建立的论证路径。结果:方法论章节的细目被打散重组,讨论部分的递进逻辑被压平。
论证被替换。 这是比结构偏离更隐蔽的损伤。AI 在处理复杂论证时,偏好将不确定性高的表述「平滑」为更常规的论断。于是,一个带有审慎限定的反常识发现,可能被改写成一个平淡的共识陈述。作者重读时未必立刻发现,因为句子本身读起来很通顺。
引用丢失。 正文中的 [1]、[3-5] 或 (作者, 年份) 标记在全文重写过程中极易被误删除、合并或移位。事后逐条核对参考文献的工程量,有时比重写还大。更糟糕的是,AI 偶尔会「补」出原文不存在的引用——这些幻觉引用混在正常标注中,需逐一在数据库里验证。
风格漂移。 全文重写的输出风格趋近于模型训练数据中的「平均化学术腔」——通常是美式社科期刊偏好的短句、直陈和固定转接语。如果原文带有特定的学科修辞传统(如德式长句论证、法理推演风格,或中文论说文中「破立」结构),这些痕迹会被一并抹平。
这四种失控指向同一个根源:AI 在缺少作者判断锚点的情况下对全文进行了无差别处理。 作者交出的是整篇稿件,拿回的也是整篇稿件,中间的修改决策完全不可见。
逐段修改:把判断权留在自己手里
逐段修改的逻辑并不复杂,但它与「复制到聊天框逐段处理」有本质区别。后者只是把全文重写拆成了若干次执行,作者依然要在聊天框与稿件文件之间来回比对、粘贴、检查,修改的可追溯性并未提升。
真正意义上的逐段修改是一套工作范式,其核心假设是:
作者保留对每一处修改的判断权,AI 在局部上下文中工作,每一步产出可审阅、可采纳、可撤销。
这个范式下,作者的角色是改稿决策者,AI 的角色是改稿执行助理。作者决定改哪里、用什么方式改、是否采纳结果、何时停止——而非将稿件整体托管给模型。
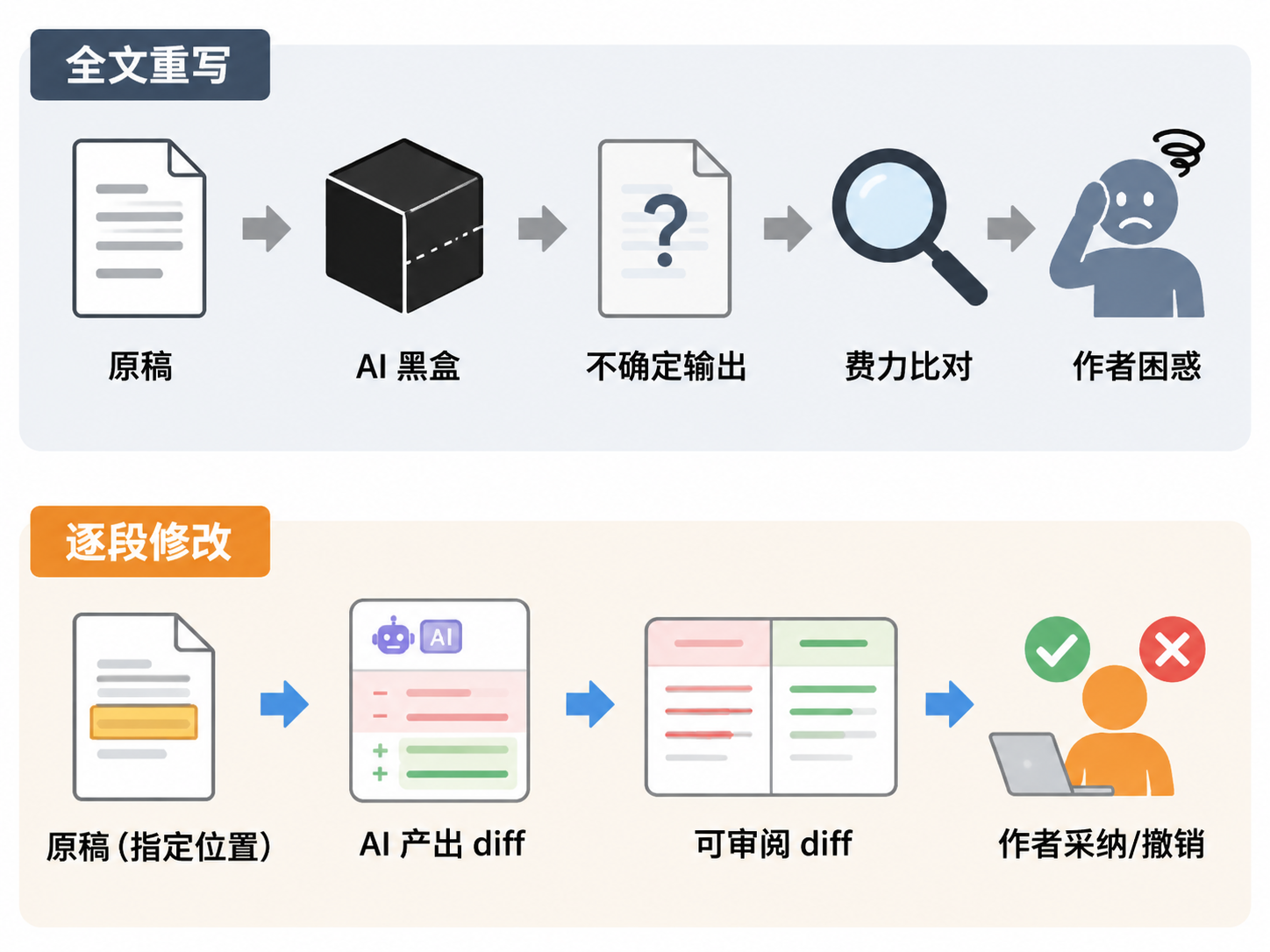
这与「一键生成」「全文润色」的根本分野在于:前者把写作视为一个需要人工判断的认知过程,后者把写作视为一个可以通过输入产出比优化的生产任务。
方法论如何落地:精确补丁与可审阅修改
将逐段修改从理念变成日常工作方式,需要工具层提供几个关键能力。
第一,AI 必须在稿件内工作,而非在稿件外。 聊天框不承载稿件本体。当 AI 的输入是复制来的段落、输出是聊天框里的文本块,作者就注定要承受复制、粘贴、比对的摩擦。稿件本身应当成为工作现场——AI 直接读取文档中的指定段落或行号,在其上下文中产出修改。
第二,修改产出必须是可审阅的 diff,而非覆盖式替换。 严肃改稿不能接受「输出替换原文」这一种交付形态。工具应产出精确的补丁(patch),展示删除了什么、增加了什么、修改发生在哪里,并允许作者逐条采纳、撤销或重试。这意味着每一处改动都有据可查,作者不需要逐字比对两个版本。
第三,引用关系必须在修改过程中持续校验。 参考文献不是导出时才处理的后端问题。正文中的 [@alias] 标记与资料库之间应维持实时绑定。当 AI 修改了包含引用的段落时,工具需要能够提示:某条引用已无对应来源(orphan)、某条资料未被任何正文引用(dangling)、引用标记是否与资料库条目一一对应(bound)。这种核对将引用从静态的「文末列表」变成动态的写作约束。
InkFount 作为面向中文研究型写作的 AI 工作台,正是围绕这一范式构建的。其核心机制是 read_outline / read_lines / replace_text 等受控工具:AI 基于已有稿件结构读取内容,在指定范围内生成修改,并以 diff 形态交付给作者审阅。修改发生在正文上下文中,不必离开文档切到聊天界面。
Markdown:长文修改的结构锚点
Markdown 在这套流程中扮演的角色常被低估。它不是一个「轻量标记语言」的选择偏好问题,而是结构控制层的工程决策。
对于动辄上万字的研究型长文,AI 需要在「读取第 2.3 节的第三段至第五段」这个粒度上精准定位。Markdown 的标题层级(# → ## → ###)为 AI 提供了天然的锚点体系,使得「修改文献综述部分对张三 2023 的评述」这类指令可以精确转化为对特定行范围的操作。相比之下,富文本或纯文本文档缺乏这种可解析的结构层级,AI 只能依赖语义猜测来定位段落边界。
对于中文研究者而言,Markdown 的另一个价值在于:它降低了结构化长文写作的门槛。不需要学习 LaTeX 语法,也能获得章节分明、可被 AI 精确寻址的稿件形态。最终输出时,Markdown 结构可以直接映射为 Word 或 PDF 的样式体系。
改完稿之后:从修改到交付的闭环
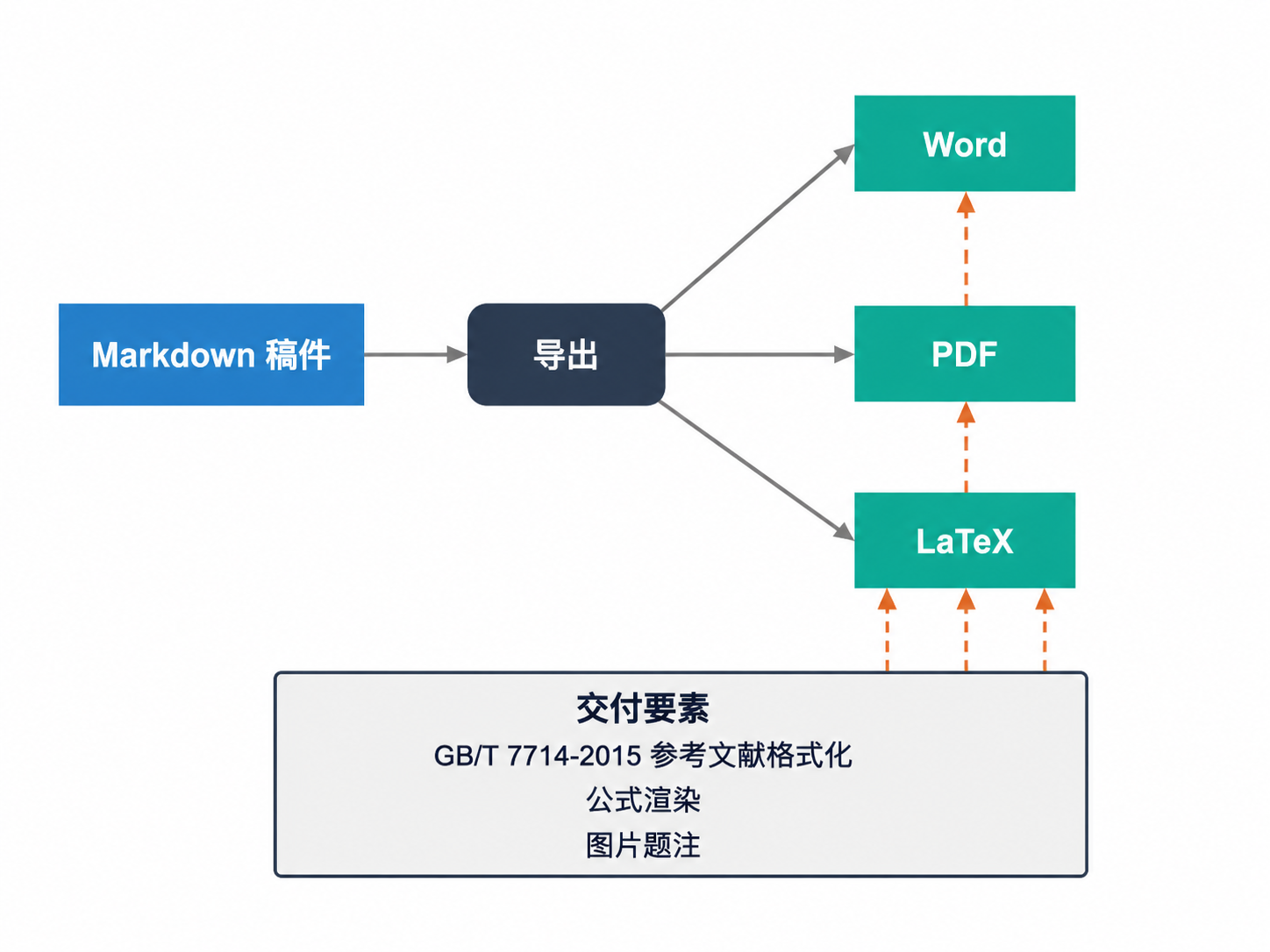
一篇论文的终点不是改完稿,而是交得出去。中文研究者面对的现实交付需求包括:Word 文档用于导师批注和学校系统提交、PDF 用于打印和送审、LaTeX 用于特定期刊的排版要求、参考文献必须符合 GB/T 7714-2015 著录规则。
如果 AI 修改环节和最终交付环节分属不同工具链,就需要额外的人力在导出后调整格式、核对引用、修复转换过程中丢失的公式编号。InkFount 在稿件完成后直接支持 Word / PDF / LaTeX 三种导出路径,参考文献按 GB/T 7714-2015 标准格式化,公式保留渲染结果,图片与题注保持关联——避免「改完了却交不出去」的最后一公里断裂。
不只是一个操作习惯
从全文重写转向逐段修改,表面上只是改变了与 AI 的交互方式。往深处看,它回答的是学术写作场景中一个被长期悬置的问题:AI 辅助写作的伦理边界在哪里?
当工具让你可以在每一次修改中看到改了什么、决定用不用、保留撤回的权利,它就不是在替你写作,而是在帮你改稿。这条边界对研究者而言不是束缚,是保护——保护的是你对自己论证的最终解释权。
把写作主权握在手里,把重复劳动交给工具。这大概是 AI 进入学术写作时,最值得争取的一种关系。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
AI论文扩写不注水:用研究型写作工作台实现可控扩展
拆解AI论文扩写与注水的本质区别,介绍精确改稿、引用核对、Markdown长文写作等可操作技巧,帮助研究生在扩展篇幅的同时守住学术严谨性。
AI论文创作保持原创性:关键不在拒绝AI,而在守住写作主权
AIGC检测焦虑背后,真正的问题是作者是否对AI的每一处修改知情、可控、可追溯。本文拆解写作主权的三层防线,并介绍研究型写作工作台InkFount如何将其落地。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。