AI润色与学术不端之间,隔着一道可追溯的门
区分合理AI润色与学术不端的核心不在检测分数,而在作者能否逐条回溯并辩护每一次修改。本文给出可操作的三个判断标准。

如果你最近被AIGC检测四个字压得喘不过气,放心,你并不特殊。2024年以来,越来越多高校将AIGC检测纳入论文审核流程,研究生群里关于“AI率多少算安全”的讨论从深夜延续到凌晨。有人在阈值数字里寻找安全感,有人在各种“降AI率”教程中越陷越深,还有人在焦虑中放弃了AI辅助写作的全部可能性——宁可手敲每一个句子,也不愿冒被标记的风险。
这些反应都是真实的,但它们指向了同一个误区:把学术合规问题简化成了检测分数问题。
一条真正可操作的边界,不在检测报告的数字上,而在一个更根本的问题里:你能否逐条回溯并辩护每一次AI修改?

阈值焦虑掩盖了真问题
围绕AIGC检测的公开讨论,大量集中在“合理阈值”上。10%、15%、30%——不同机构给出不同参考线,自媒体据此生产了大量“AI率解读”内容。但把合规等同于控制百分比,本质上是在用检测工具的逻辑替代学术伦理的逻辑。
检测工具衡量的是文本层面的模式相似度,而学术诚信衡量的是作者行为层面的可解释性。二者不重合。一个完全由AI生成、经人工反复改写后避开检测的段落,分数可能很低,但学术上问题很大;一段由作者撰写、AI仅做了句法微调且每处改动都可追溯的文字,即便被检测标记,作者也能逐条说明改了什么、为什么保留。
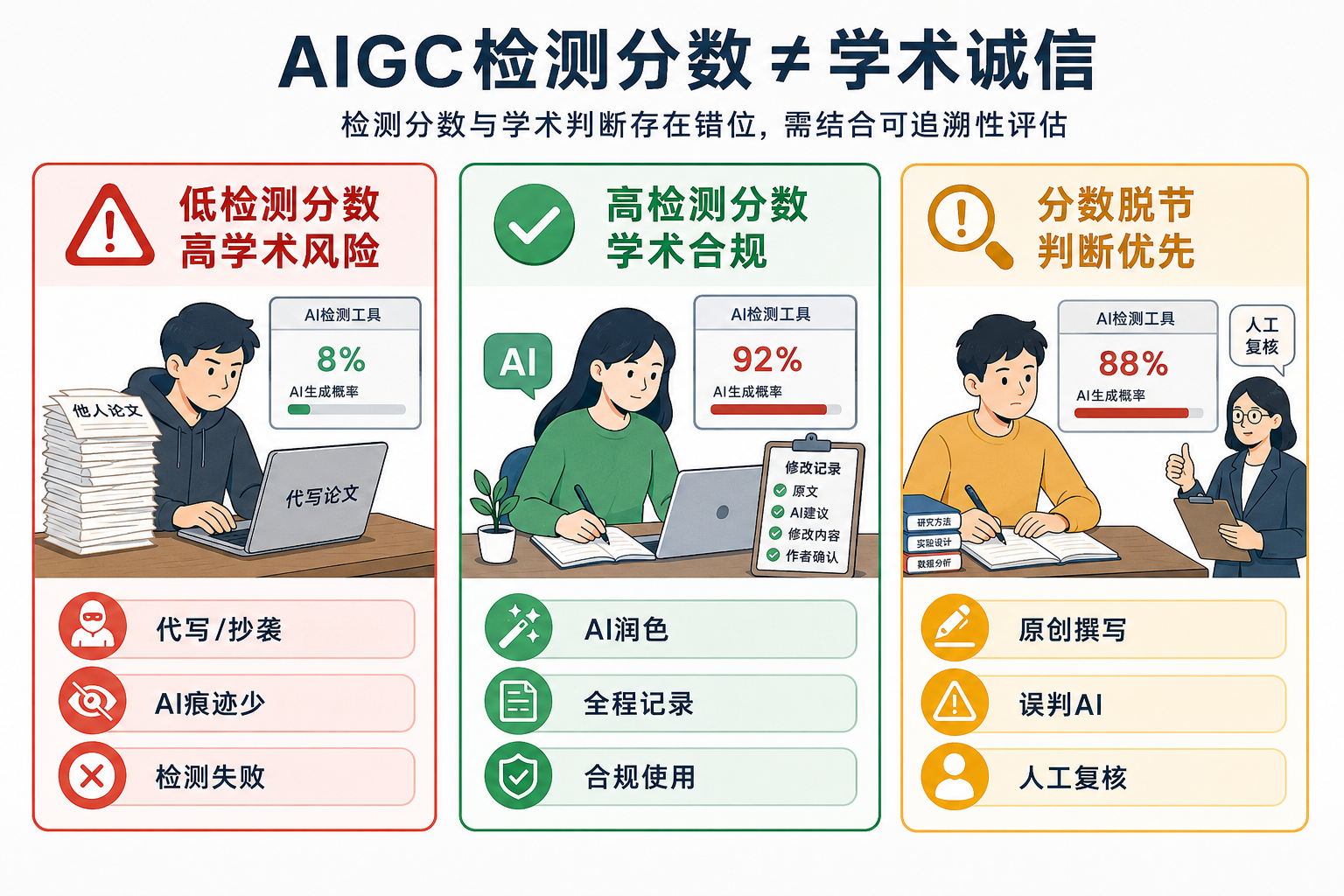
可辩护性,而不是检测分数,才是合理润色与学术不端的分水岭。
可控:AI改了什么,你说了算
合理润色的第一条操作标准是“可控”——作者对AI的每一次修改输出都保留采纳、修改或撤销的最终决定权。
这听起来像一句正确的废话,但把它落到写作工具的操作层面对比一下,差距就出来了。
一种模式是:AI接收作者的初稿,返回一段润色后的完整文本,覆盖原文。作者面对的是一个“结果”,不知道AI改了哪些地方、为什么改、哪些改动是必要的而哪些是过度干预。另一种模式是:AI围绕已有稿件进行精确修改,每处改动以diff形式呈现——插入、删除、替换逐一列出,作者逐条审阅,点击采纳或撤销。
前者把判断权外包给了模型。后者把判断权留在了作者手中。
这不仅仅是用户体验的差别。从学术伦理的角度看,前者模糊了作者与AI之间的责任边界——如果一段文字被整体改写而你无法还原每一处修改的决策过程,你就无法为自己的稿件做完整辩护。后者则保留了完整的决策链:你知道AI在哪一行做了什么,你决定哪些留下、哪些退回、哪些二次修改。
可控不是一个抽象原则,而是一个可以被设计进工具交互中的机制。InkFount在这一点上的选择是明确的:AI以精确patch的方式工作,输出diff而不是覆盖性改写,作者在正文语境中逐条审阅,每一步采纳或撤销都被记录。写作主权——这个常被提及但鲜少被定义的概念——在这里被翻译成了一个可操作的交互流程。
可审:AI的参与经得起还原
可审是第二道防线。它回答的问题是:如果答辩委员、导师或期刊编辑追问“AI在你这篇稿件里具体做了什么”,你能不能拿出比“我用AI润色了一下”更具体的回答。
许多AI写作工具在“透明性”上止步于声明层面——在方法或致谢中标注“本文使用了XX工具进行语言润色”。但声明不等于可审。声明告诉别人你用了AI,可审告诉别人AI具体做了什么、你在每一步如何决策。
可审的实现需要两个层面的支撑。第一,AI的每一次交互过程需要留下记录——不是聊天记录的截图堆砌,而是结构化的、可按步骤回溯的过程日志。InkFount的做法是将AI工作过程通过SSE(Server-Sent Events)逐阶段展示:thinking(模型推理)、tool_call(工具调用,如读取稿件段落、搜索替换)、tool_output(工具返回结果),每一轮修改结束后收口为Summary Bar,关键状态持久化保存。
这意味着,一篇稿件从初稿到终稿之间AI参与的所有修改,都有一条可还原的时间线——不是事后回忆,而是写作过程中的自动留痕。
第二,可审与可控是相互强化的。逐条diff的审阅机制天然产生了一条决策记录:哪些改动被采纳、哪些被拒绝、哪些被二次编辑。把这两层加在一起,作者面对审查时拿出的不是一个笼统的声明,而是一份可追溯的修改日志。
可追溯:引用不能是悬空的
在AI辅助写作的合规讨论中,引用往往被低估。大多数讨论聚焦在正文的AI生成比例上,而引用仅被视为最后的格式化环节。这忽略了一个事实:引用层面的断裂——正文标注了来源但参考文献中没有对应条目,或参考文献列表中有条目但正文从未引用——本身就是学术规范的红线。
AI在辅助改写、重组段落时,可能在不经意间造成引用断裂。比如,AI在整合两个段落时删去了一句带有引用的句子,但参考文献条目未被同步清理;或者AI在补充论述时建议引用某篇文献,但该文献并未被录入资料库,最终出现在参考文献列表中却没有对应的正文标记。
这些问题的严重性在于它们极难被作者手动发现。一篇两万字的论文,几十条参考文献,逐一核对正文引用与参考文献列表的对应关系,是极其耗时且容易遗漏的工作。
InkFount的引用核对机制针对的正是这个问题。正文中的引用标记[@alias]与资料库条目绑定,系统实时追踪三种状态:bound(正文引用与资料库条目匹配)、orphan(正文引用了某条资料但该资料未被收入资料库)、dangling(资料库中存在某条目但正文没有引用它)。三态校验让引用层面的断裂在写作过程中就被暴露出来,而不是等到终稿提交前才被发现。
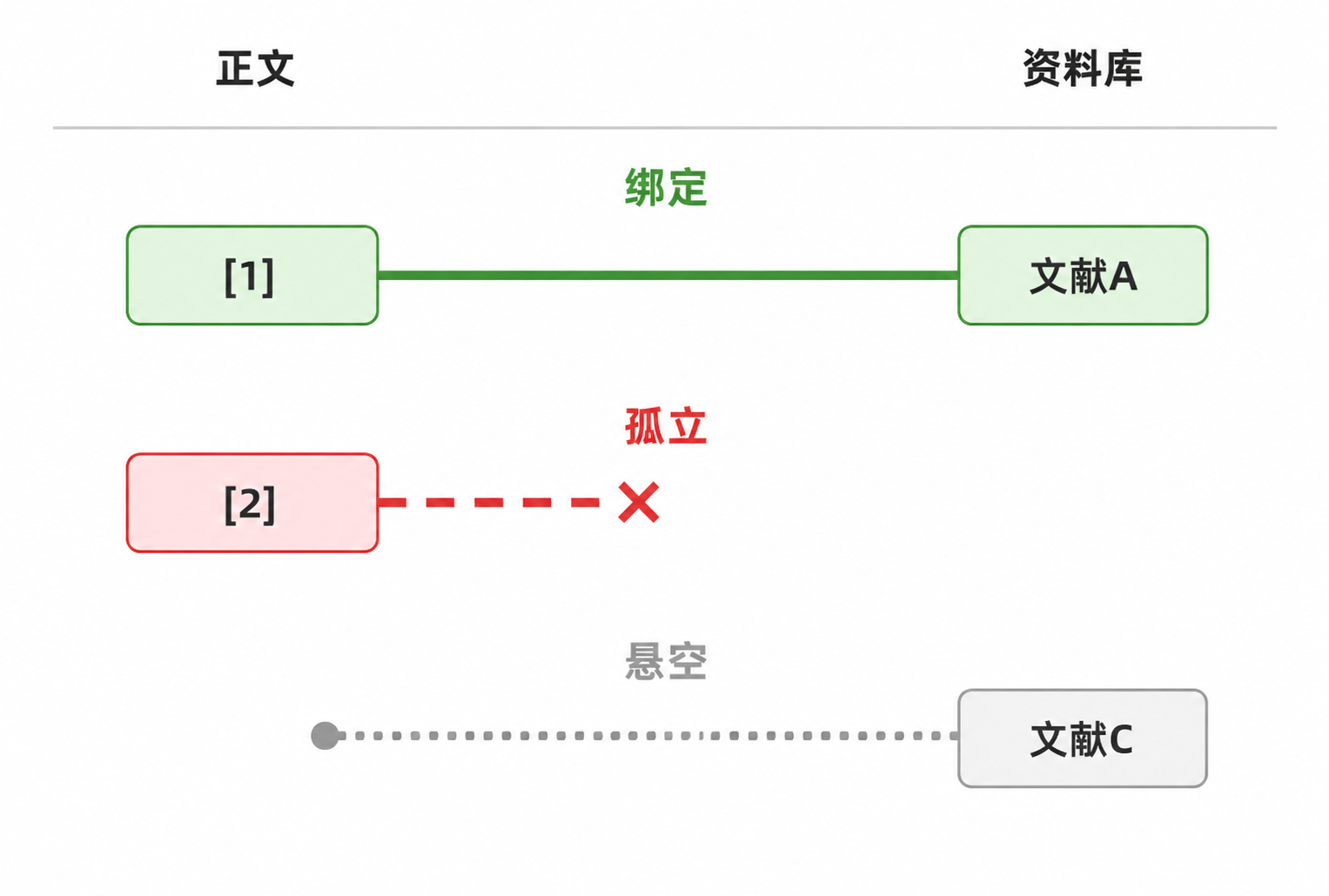
可追溯的完整含义是:正文中的每一个引用主张,都能在资料库中找到对应的来源;资料库中的每一条收录文献,都在正文中有明确的引用点。这不是技术炫技,而是学术写作的基本功——只不过在AI介入改写、重组、扩展的过程中,这项基本功需要工具的辅助来守住。
边界不在工具,在处理方式
回到最初的问题:合理AI润色与学术不端之间,一线之隔在哪里?
线不画在“AI做了什么事”上——语言润色、结构调整、表述优化,这些行为本身不构成学术不端。线画在“作者能否为AI参与的内容承担完整的学术责任”上。
如果你的AI辅助写作过程是这样的:你把一段初稿交给AI,AI返回一段改好的文字覆盖原文,你不知道具体改了什么,也拿不出修改过程的记录,参考文献里有一些你记不清是什么时候加进去的条目——那么无论AIGC检测分数多低,你已经走在了学术不端的边缘。不是因为AI做了什么坏事,而是因为你放弃了对稿件的解释权。
如果过程是这样的:AI围绕你的稿件进行精确修改,每处改动以diff呈现,你逐条审阅并决定采纳或撤销,修改过程留下结构化日志,正文引用与资料库持续核对无断裂——那么即使AIGC检测工具标记了某些段落,你也有充分的依据去说明AI的实际参与范围和你的审阅决策。
两种过程的本质差异不在技术先进程度,而在是否将“可辩护性”设计为工具的核心机制。InkFount的定位——研究型写作工作台而非一键生成器——正是这一逻辑的产品化表达。它不替代作者思考,不产出不可追溯的文本,不在后台静默改写后输出一个“干净”的结果。它把稿件的现场交给作者,把修改记录摊开在桌面上,把引用关系持续暴露在视线之内。
合规不是一个需要你小心翼翼揣测的数字游戏。合规是一个过程问题:你写的每一句话,你都知道它为什么在那里。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
学术论文图表格式规范全解:表题、图题与数据来源标注的正确方法
图表格式不规范是论文被退回的高频原因。本文系统讲解表题与图题的位置和编号规则、三线表规范、数据来源的三种标注方法,并从写作流程角度分析如何避免图表返工。
论文引用核对清单:用 bound / orphan / dangling 三态法逐项检查,交稿不返工
一份可直接执行的引用核对清单,掌握 bound / orphan / dangling 三态校验,确保正文引用与参考文献一一对应,符合 GB/T 7714-2015,降低交稿返工风险。
学术论文摘要怎么写?GB/T 6447-2025 新国标下的结构、字数与关键词策略
基于2026年实施的GB/T 6447-2025《文献摘要编写规则》,系统讲解学术论文摘要的结构(目的-方法-结果-结论)、字数规范与关键词选取策略,帮助研究者写出符合期刊要求且检索友好的摘要。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。