Claude Code、Codex 写论文?别让代码工具耽误你的学术写作
Claude Code 和 OpenAI Codex 是编程利器,但用来写论文只会事倍功半。本文从论文的多元素构成、引用核对、格式交付等角度,解释为何代码生成工具不适合学术写作,并推荐专为中文研究型写作设计的 InkFount。

最近半年,Claude Code 和 OpenAI Codex 在开发者社区的热度一浪高过一浪。它们能在终端里理解整个仓库、自动修改代码、生成测试,让不少写代码的人直呼“生产力革命”。一些研究生和科研人员因此产生联想:既然这些 AI 能搞定复杂的编程任务,写论文是不是也不在话下?但这个念头从一开始就踩进了工具的错配区。Claude Code 和 Codex 从架构到交互都为代码生成而优化,与学术论文的多元结构存在根本错配——论文不是纯文本,它包含公式、图表、参考文献和严格的格式交付要求。真正适合科研写作的,是以稿件为工作现场、支持引用核对和多格式导出的专用写作工作台,而不是代码补全工具。
热度之下:为什么有人想用编程 AI 写论文?
在各类技术分享和社交平台上,Claude Code 被描述为能够跨文件理解项目、自动完成重构的终端 Agent;Codex 则凭借自然语言到代码的翻译能力,大幅降低了非程序员写脚本的门槛。这类工具的火爆很容易让人产生一种错觉:只要有足够长、足够复杂的提示,它们也可以写出合格的论文段落。
一些同学开始尝试将论文提纲粘贴进提示窗口,让 Codex 生成综述段落,或者用 Claude Code 在 Markdown 文件中“修改”语句。短文本的流畅度确实惊艳,但只要一推进到完整的章节,问题就迅速暴露:工具不理解章节间的逻辑递进,无法感知图表与正文的对应,更谈不上自动管理引用。整件事的本质是:代码生成工具的设计假设是一段段可以独立编译的代码块,而论文是一个相互缠绕、需要持续上下文关联的多元素综合体。这决定了泛化使用的边界。
代码工具的本质:为仓库而生,不为稿件设计
要理解为什么 Claude Code 和 Codex 很难胜任论文写作,得先看清它们的产品基因。
Claude Code 的定位是命令行里的编程 Agent:它默认操作的对象是代码仓库,交互以终端指令和 diff/patch 为中心。它的优势在于对仓库级上下文的建模,能理解函数之间的调用关系、识别代码风格,但这一切都建立在编程语言的可解析结构上。而一篇论文的“上下文”不是函数调用,是段落之间的论证链条、图表与文字之间的重复引用、引用来源与正文论点的对应关系——这种语义关联无法用抽象语法树来表达。
OpenAI Codex 的主要落地场景是代码补全和生成,用户通过 API 传入自然语言注释或部分代码,它返回后续实现。它的训练数据以代码为主,交互模式是“一次输入,一次生成”。这更适合处理边界清晰的小段任务,而写论文需要的是围绕一个弹性大纲进行多轮迭代、在每个节点上接受外部反馈并精细修改——它天然需要一种能持续追踪稿件版本、呈现修改痕迹、允许局部撤销的工作方式。
把这两款编程 AI 直接搬进论文写作流程,相当于让瓦工的木锯去裁布料——工具本身没有问题,但场景选错了。
论文不是纯文本:图表、公式、参考文献的真实挑战
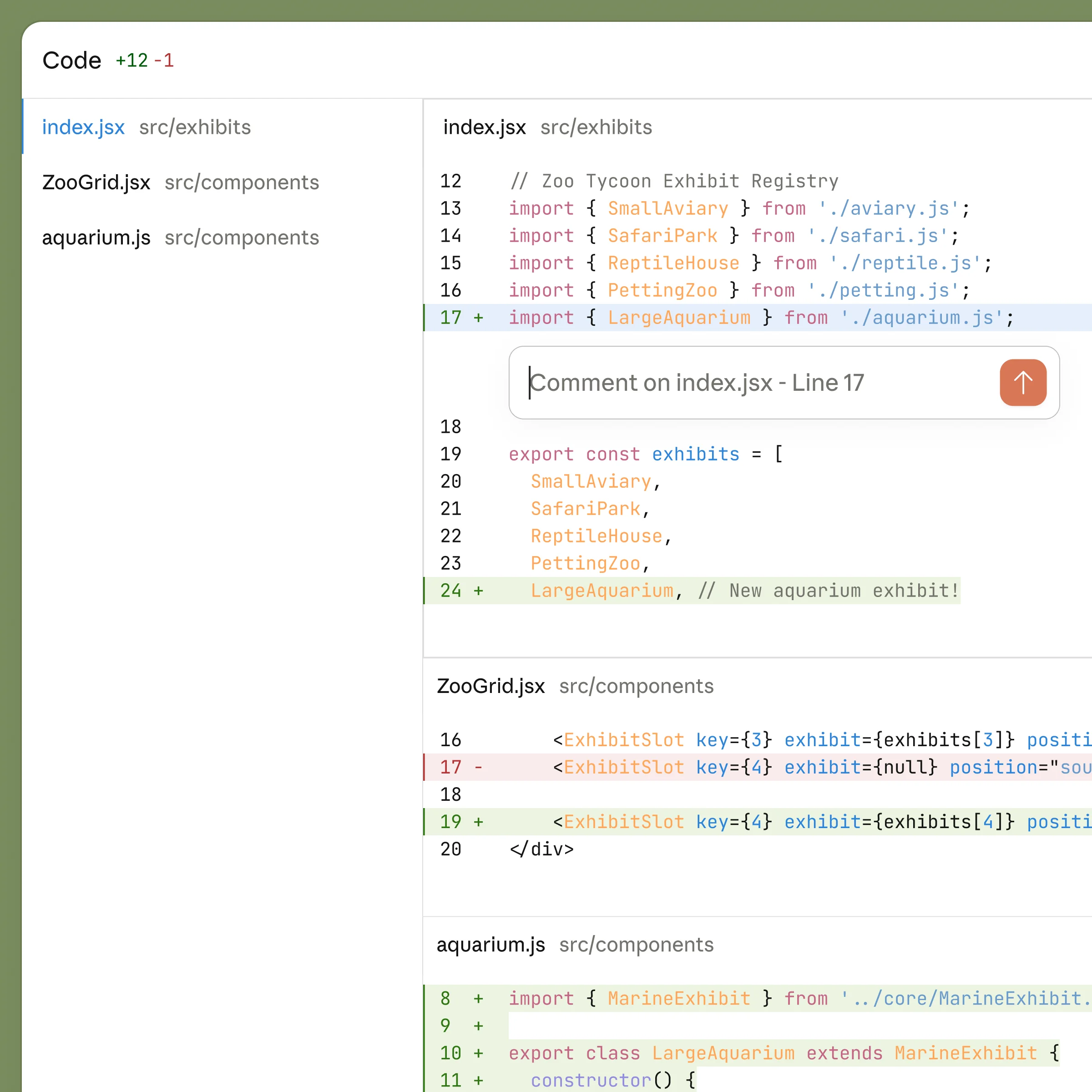
学术论文从来不是一连串文字。一个典型的研究型稿件通常包含:带编号的图表和题注、内嵌的数学公式(可能是 LaTeX 或 MathML)、交叉引用的图表与小节编号、文末的参考文献列表。这些元素彼此牵连,任何一处的变动都可能引发连锁更新。
而 Claude Code 和 Codex 对这些元素几乎没有原生处理能力。你可以让 Codex 生成一段 LaTeX 公式代码,但它不会帮你检查公式是否正确渲染、编号是否与上下文匹配。你让 Claude Code “修改第三张图的标题”,它不知道第三张图在哪里,也不理解题注的编号体系。参考文献更是盲区:它既没有引用数据库的概念,也不会区分一条引用是正文中首次出现还是在别处被人翻出来重提。你只能自己手动在 Word 或 Zotero 里管理这一切,然后把 AI 生成的零散文本一段段拼接进去——所谓的 “AI 辅助”变成了大量的手工对齐。
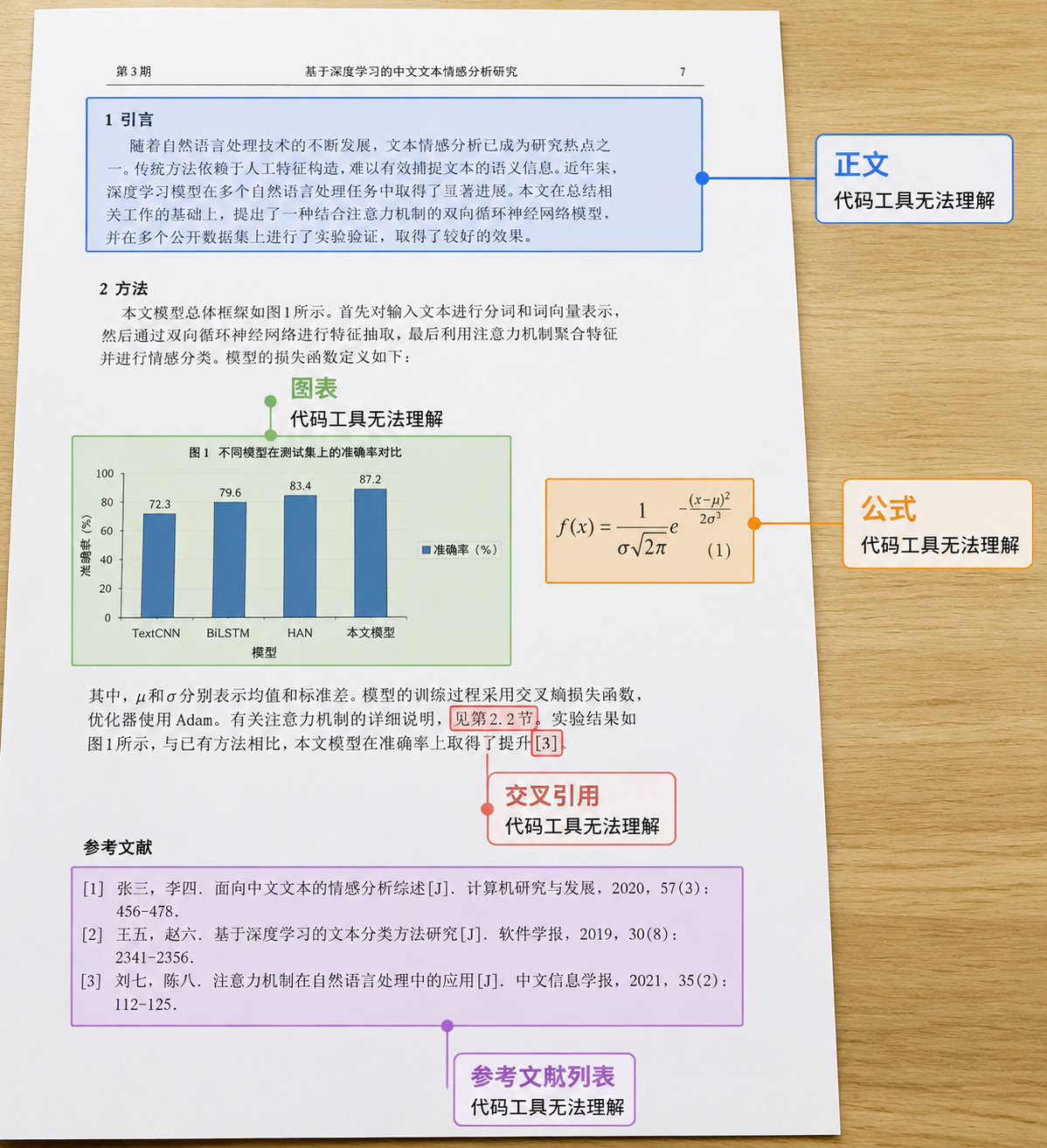
这种断裂对写作节奏的破坏很明显:你刚让 AI 修改了一个数据描述,接着就要跳出写作环境去更新图表、调整公式编号、核对引用列表。代码工具没有为这种多元素协同提供任何衔接。
专用写作工作台如何填补鸿沟——以 InkFount 为例
如果承认论文写作的核心是围绕“稿件”这个复杂文档进行的持续修订,那么专用工具的设计起点就应该是:你需要一个能容纳所有元素、随时审视修改痕迹、自动维护引用关系的工作现场。InkFount 遵循的正是这个思路。
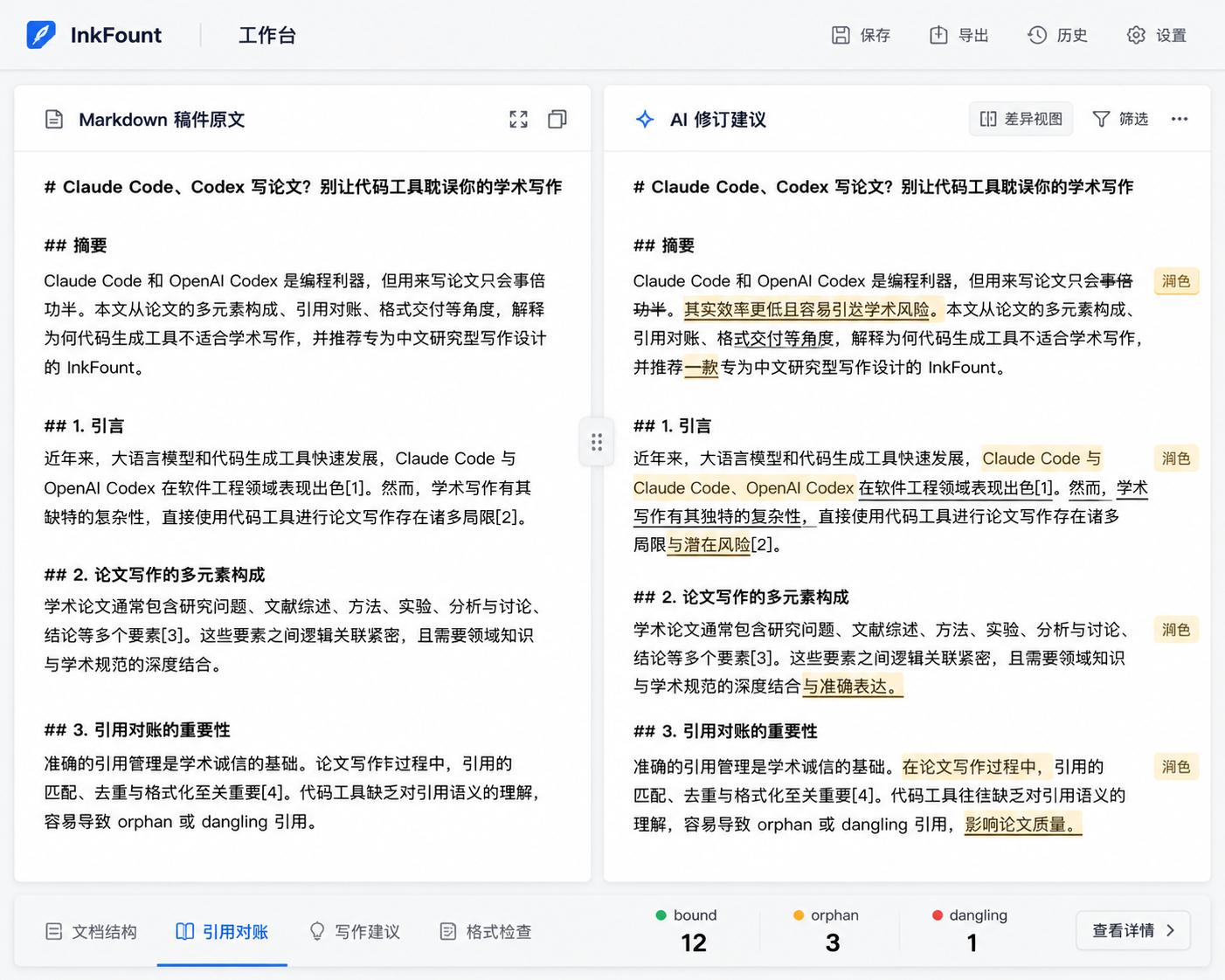
首先,InkFount 以一篇 Markdown 稿件为工作中心。它不是让你输入一个指令就输出一整段预测文本,而是让你在已有稿件上选取任意区域,发出“改得更清晰”“补充方法论说明”“压缩到 200 字”等指令,AI 会产生一个并排的修订建议,就像代码评审中的 diff 视图。你可以逐句采纳或舍弃,而不是全盘替换。这个交互的关键在于:判断权始终在你手里,AI 扮演的是提建议的审稿人,而不是替身作者。
在此基础上,InkFount 把文献引用做成了与正文强绑定的结构化资料库。每一条插入稿件中的引用,系统都会追踪其状态:正文已引且来源匹配的显示为 bound,引用遗失来源的标记为 orphan,来源未被正文引用的标记为 dangling。这意味着你不会在定稿前才发现某条文献只存在于参考文献列表里而从没在正文中出现过,也不会反过来漏引。
最后一环是成果交付。InkFount 支持将整篇稿件一键导出为 Word、PDF 或 LaTeX,参考文献自动按 GB/T 7714-2015 标准格式化。期刊要求不同格式时,只需切换模板,不需要重新排版或更换引用管理软件。这覆盖了从初稿写作到投稿的完整链路,避免了中间多次跨工具搬运带来的格式错乱和版本混乱。
场景对比:同一篇论文,两种工具的差距
设想一个常见任务:写一篇 8000 字左右的中文综述,包含 5 张分析图表和 30 条参考文献。
用 Claude Code 或 Codex 尝试的典型路径是:在终端或 API 环境中逐步生成段落,复制到本地文档,再到 Word 或 LaTeX 中插入图片、敲公式、用 Zotero 或 EndNote 补参考文献。碰上需要整体调整论证结构的情况,很容易丢失上下文,因为代码工具无法维护长文档的全局视图。引用编号的增减往往要手工核对,稍不留意就会出现编号错乱或重复引用。
而用 InkFount 的路径要流畅得多:在同一个稿件文件中写作,遇到需要改进的段落就直接要求 AI 给出修订,修改痕保留,随时可回退。插入引用时选择资料库条目,系统自动维护链接,导出时格式与引用格式一次性到位。整个过程中不必离开写作界面去处理排版或引用细节。
这种效率差别不来自 AI 模型本身的能力,而来自工作流的完整度。代码工具让你成为流程的粘合剂,专用写作工作台则让流程本身变得透明——这是“能写文字”和“能交付论文”之间的本质区别。
结语:把代码还给编程工具,把论文还给写作工作台
Claude Code 和 Codex 在它们所属的编程领域是高效的,但把编程的能力直接翻译到论文写作,是对任务复杂度的低估。论文写作不是自动补全,而是在多元元素编织的稿纸上,持续推敲、修订、核对。你需要一个看得见全貌、改得下手、引得清楚、导出从容的环境。
选工具的本质是匹配场景。如果你在写代码,请继续享受 Claude Code 和 Codex 带来的速度。如果你的面前是一篇需要交付给导师或期刊的论文,选择以稿件为核心、保留你判断权的写作工作台,才是更合理的路径。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
AI 论文改稿工具怎么选:看 diff、引用、导出,而不是看能不能一键生成
市面上的 AI 论文工具都在强调“一键生成”,但严肃学术写作的核心是改稿。本文把工具分成聊天框、一键生成工具、研究型写作工作台三类,用四个硬标准——diff 可见性、撤回能力、引用对账、可交付导出——帮你穿透营销话术,找到真正能用的改稿工具。
ChatGPT 写论文为什么总编假文献?问题不在模型,在你的写作流程
ChatGPT 生成的参考文献格式完美却查无此文?根源不是模型幻觉,而是聊天框写作让引用与正文脱节。本文从工作流角度给出可落地的解决思路。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。