免费AI论文降重工具安全吗?上传即失控与降重悖论的双重困局
免费AI降重工具看似解决了查重焦虑,却可能在隐私和学术质量上制造更大的隐患。本文拆解"上传即失控"的数据风险与"降重悖论"的成因,并探讨从源头消除降重需求的写作方式。

免费AI降重工具的隐私风险与质量风险是同一问题的两面——黑盒式事后补救既无法保护论文数据,也无法保证学术质量;真正的解法不是换一款更安全的降重工具,而是将安全前移到写作过程本身,在可控、可审、可追溯的环境中从根本上消除"需要降重"的局面。
查重报告上的红色数字,大概是论文提交前最让人心跳加速的东西。于是免费AI降重工具成了救命稻草——把论文粘贴进去,几秒钟出来一篇"面目全非"的新文本,重复率数字应声下跌。很多人到这一步就松了一口气。
但真正的问题从这一刻才开始:你的论文去哪了?改完的文本真的更"安全"了吗?
上传即失控:免费服务的商业逻辑决定了数据必然流动
免费AI写作和降重工具不是慈善产品。威斯康星大学麦迪逊分校法律事务部门在面向师生的数据隐私指引中直言:免费生成式AI工具不提供企业级付费工具所具备的数据安全与合同保护。换句话说,"免费"的代价往往是用户数据。
2026年初,数据隐私研究机构Incogni对Chrome商店中442款标注"AI驱动"的扩展程序进行了系统性隐私审计,结论令人警惕:52%的工具至少收集一类用户数据,29%收集了个人可识别信息。在写作辅助类目中,Grammarly和QuillBot这两款下载量均超过200万的工具被列为隐私风险等级最高的产品。
这些数据揭示了一个结构性问题:大量免费AI工具的信息收集行为并非偶然,而是商业模式的有机组成部分。用户上传的文本可能流向几个方向——存储于服务端用于产品迭代、脱敏后进入模型训练语料池、通过广告SDK与第三方分析服务共享。平台在隐私政策中可能写明了这些用途,但中文研究生面对动辄上万字的英文或翻译腔政策文本时,真正逐条审阅并理解其后果的人极少。
更棘手的是删除的可验证性。平台可以声明"处理完成后自动删除"或"14天清除",但用户没有技术手段确认自己的论文是否已从所有备份、缓存和训练语料中彻底消失。一篇论文在上传的那一刻,就已经脱离了作者的控制范围。
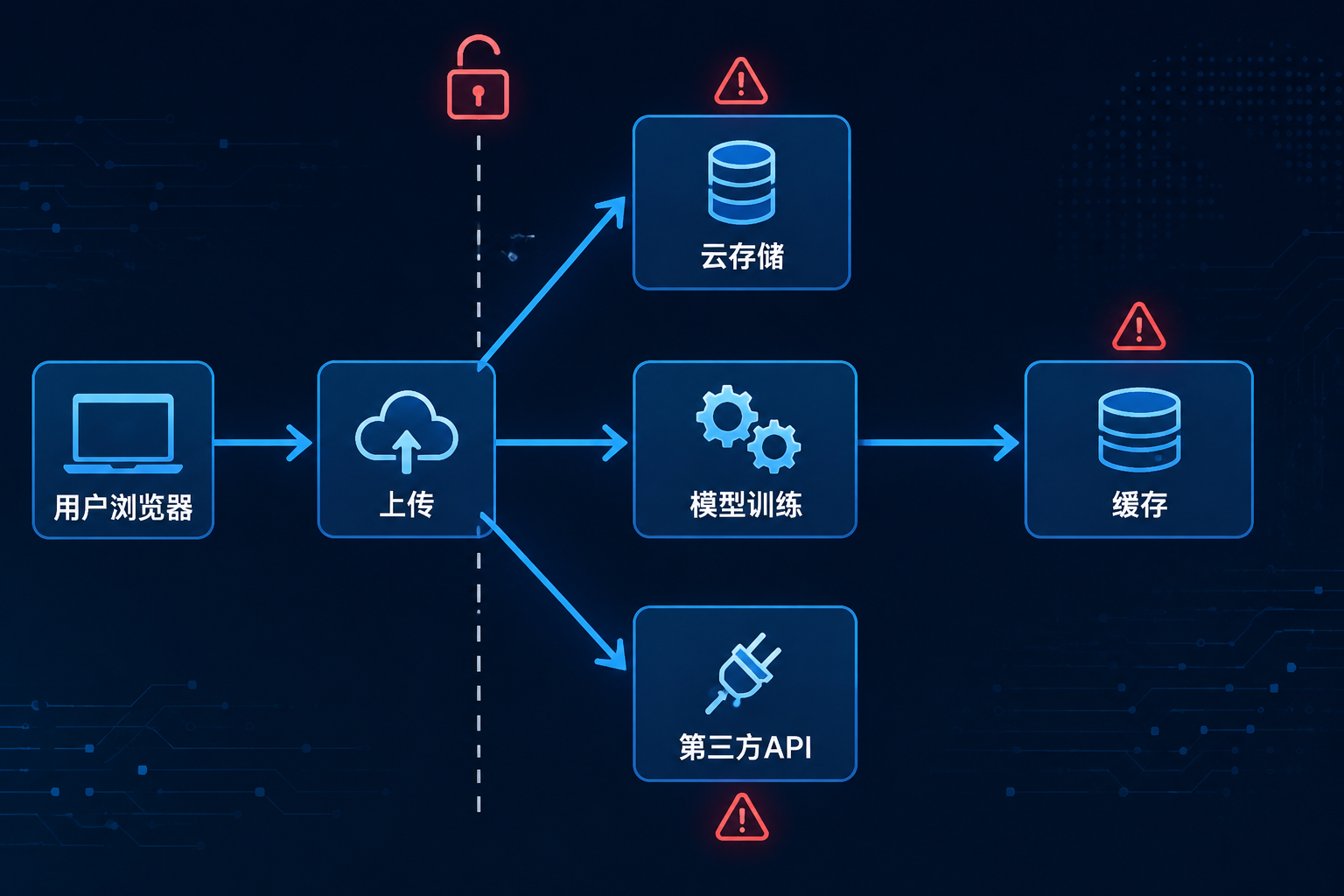
对于学位论文和未发表的研究成果,这种失控的风险并非理论推演。论文中可能包含尚未公开的实验数据、正在申请的专利技术方案,或涉及机构合作的敏感信息。一旦这些内容进入无法追溯的数据流转管道,后果远比查重率高出几个百分点严重得多。
降重悖论:黑盒改写为什么让文本越改越"AI"
如果说隐私风险是"你不知道论文去了哪",那么质量风险就是"你不知道论文变成了什么"——后者的隐蔽性更高,因为表面上的重复率确实降了。
当前主流的AIGC检测器依赖两项核心指标:困惑度(Perplexity)和突发度(Burstiness)。困惑度衡量文本中词汇选择的可预测性——语言模型生成的文本倾向于选择概率最高的词,因而困惑度偏低;突发度衡量句子长度和结构的变化幅度——AI文本的句式往往均匀整齐,缺少人类写作中因思维跳跃产生的节奏波动。检测器通过在这两个维度上比对文本与已知AI生成模式的距离,给出AIGC判定分数。
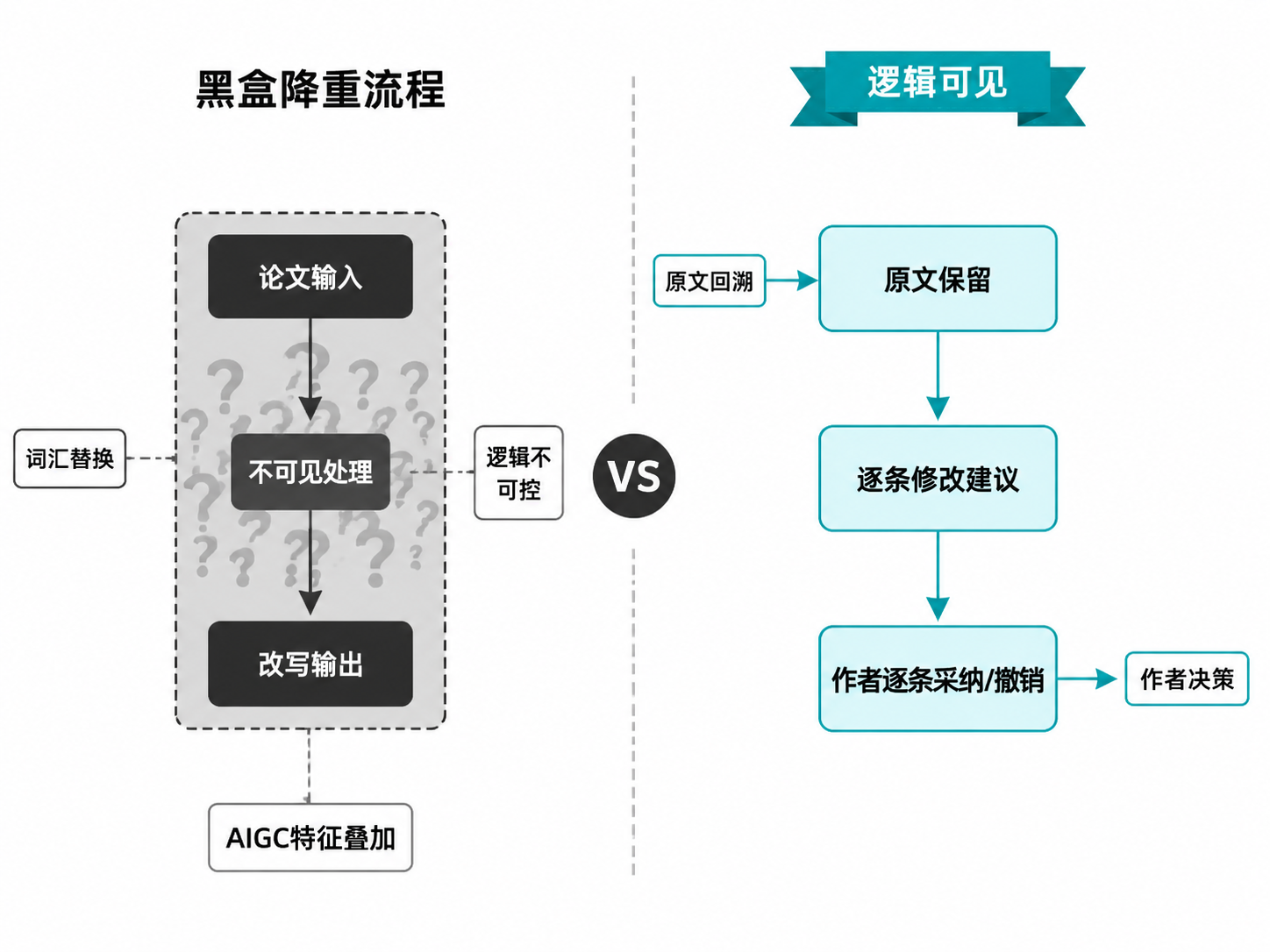
免费降重工具本身就是一个语言模型。当它接收一篇可能已经带有AI痕迹的论文并执行同义替换、句式重组操作时,输出的文本在困惑度和突发度上的表现大概率仍然落在AI文本的特征区间内。这不是"去除"AI痕迹,而是在已有AI特征上叠加一层新的AI特征。国内多个技术社区的实测记录反复印证了这一现象:用某个AI模型写的稿子,再用同源或类似模型去改写,AIGC检测率不降反升。
更大的隐患在于多轮改写的叠加效应。黑盒工具不关心段落之间的论证逻辑,它只关心如何在词汇层面把"相似度"压下去。于是术语被错误替换、学术表达的精确性让位于"足够不一样"、论证链条在逐句改写中悄然断裂。一篇经过多轮"一键降重"的论文,作者自己可能已经无法逐句复述其准确含义。
根本矛盾:事后补救无法修复过程缺陷
高查重率很少仅仅是文字表述的问题。它往往指向写作过程中的结构性缺陷:引用标注缺失、观点来源模糊、改写策略不当,或者论文自身缺乏足够的原创论证。
免费AI降重工具解决的是最表面的症状——重复率数字,而完全不触及病因。不仅如此,它还会引入新的不可控变量:你不知道哪些句子被改动了、为什么要这样改、改动后是否还准确传达了原意。在答辩或审稿环节面对追问时,这种对自身文本的失控会暴露无遗。
一个常被忽视的问题是引用与参考文献的核对。论文初稿中可能存在"正文标注了引用但参考文献列表遗漏了该条目"或"资料库中收录了某篇文献但正文从未引用"的情况。这些问题比查重率数字更关乎学术诚信的根本,却在降重讨论中几乎从未被提及——引用被当成排版阶段的格式化问题,而不是写作过程中的来源校验问题。
把安全前移:从"改好一篇稿子"到"写好一篇稿子"
解决思路的转向其实很清晰:如果高查重率源于写作过程缺乏控制,解法就应该是建立一个可控的写作过程,而不是在事后找一个不可控的工具来补救。这意味着三件事:
- 写作阶段就确保引用可追溯,而不是写完再回头补标注。
- 修改时能看到每一次改动的来龙去脉,能逐条判断采纳还是拒绝。
- 论文数据始终在自己可控的范围内,不会因为一次粘贴就失去所有权。
这恰恰是研究型写作工作台与降重工具的本质区别。以降重为目的的工具围绕"改写"设计产品;以写作为目的的工作台围绕"过程控制"设计产品。前者的输入是一篇需要"洗"一遍的稿子,后者的输入是作者从零构建的原创文本。
在可控环境中写作:InkFount的设计逻辑
InkFount的定位不是另一款降重工具——它从设计上就不提供"一键改写整篇论文"的功能。它是一个研究型写作工作台,核心假设是:论文安全与学术质量应该由写作过程本身来保障,而不是靠提交前的最后一次补救。
稿件的物理位置决定安全边界。 InkFount的游客模式将稿件存储在浏览器本地——未登录用户的论文不会离开自己的电脑,刷新不丢、关闭浏览器后依然存在。这意味着从源头切断了论文上传至第三方服务器的路径。用户可以选择在本地完成全部写作和修改,只在需要AI辅助时才发起可控的请求。
AI改稿是可审阅的,不是黑盒的。 当用户需要AI协助润色、调整结构或重写某个段落时,AI通过读取稿件结构、定位到具体行段、输出逐条修改建议来工作。每一条修改都以diff形式呈现——原文和改后文本并列,用户逐条选择采纳、撤销或要求重试。这种机制保留了作者对每一处改动的知情权和决策权,避免了黑盒改写带来的文本失控。

引用核对把学术诚信嵌入写作流程。 论文中的引用标注通过[@alias]与资料库中的来源条目绑定,系统实时检验三个状态:引用有来源、资料被使用、引用与资料一致。写作者可以随时发现"正文引用了但资料库中没有对应条目"或"资料库收录了但正文从未引用"的异常。这个设计把参考文献从"排版阶段的格式化问题"重新定义为"写作过程中的学术诚信问题"。
从写作到交稿的完整链路。 论文完成后,InkFount支持导出为Word文档、PDF文件或LaTeX源码,参考文献按GB/T 7714-2015标准格式化。从第一行Markdown写作到最终提交给学校或期刊的格式文件,整个过程不需要把论文内容粘贴到另一个平台去做排版或引用处理,减少了数据暴露面和格式返工。
重新理解"降重":最好的降重是不需要降重
免费AI降重工具的吸引力在于它提供了看似零成本的捷径。但"零成本"的背后,是数据离开控制范围的隐私成本和文本失去学术准确性的质量成本——而这两者都源于同一个设计缺陷:黑盒式的事后处理。
Incogni的审计数据和UW-Madison的法律指引都指向同一个结论:免费AI工具的数据实践缺乏用户可验证的透明度。而AIGC检测器的技术原理则解释了为什么用AI去"洗"AI痕迹只会适得其反。这两条线索交汇处,是一个清晰的判断:依赖免费降重工具是治标不治本的策略,它解决一个问题的同时制造了两个更大的问题。
真正的解法从一开始就不一样——在一个可控、可审、可追溯的环境中写作。当引用在写作过程中逐一绑定来源,当每一次修改都经过作者本人的审视和确认,当论文数据从未离开过自己掌控的范围,"需要降重"的局面就不会出现。InkFount提供的正是这样一个工作台:它不是帮你修稿子,而是帮你写出不需要大修的稿子。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
AI 论文改稿工具怎么选:看 diff、引用、导出,而不是看能不能一键生成
市面上的 AI 论文工具都在强调“一键生成”,但严肃学术写作的核心是改稿。本文把工具分成聊天框、一键生成工具、研究型写作工作台三类,用四个硬标准——diff 可见性、撤回能力、引用对账、可交付导出——帮你穿透营销话术,找到真正能用的改稿工具。
ChatGPT 写论文为什么总编假文献?问题不在模型,在你的写作流程
ChatGPT 生成的参考文献格式完美却查无此文?根源不是模型幻觉,而是聊天框写作让引用与正文脱节。本文从工作流角度给出可落地的解决思路。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。