GB/T 7714引用核对:不是格式问题,是绑定问题
中文论文参考文献检查的核心不是格式规范,而是正文引用与资料来源之间的绑定关系。本文提出Bound/Orphan/Dangling三态诊断框架,帮助写作者在写作过程中系统消除引用遗漏与错配。

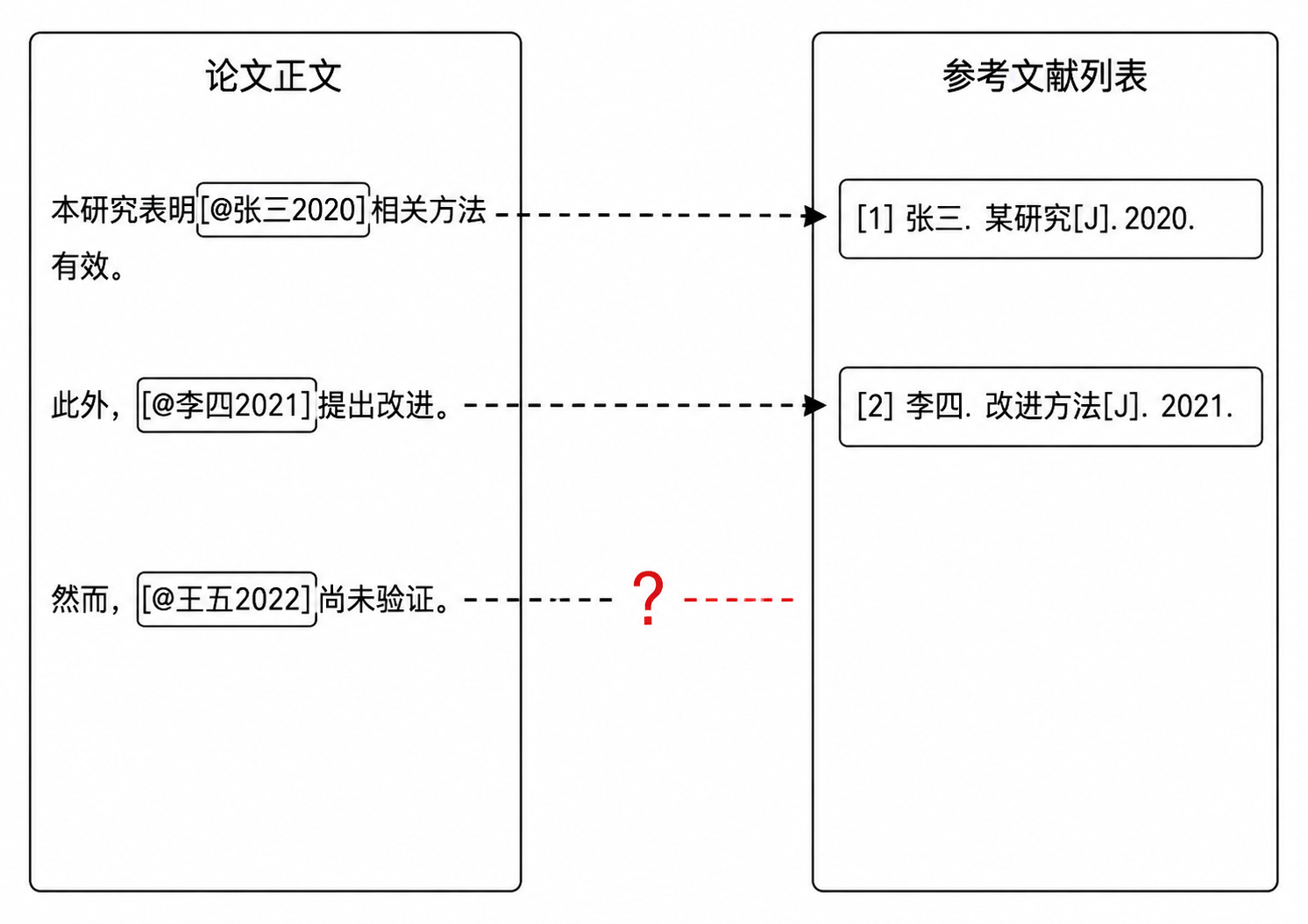
写完论文初稿后,大多数中文研究生会进入同一个环节:把正文里的引用标记和文末的参考文献列表逐条比对。几十条甚至上百条引用,一条一条查过去——这条正文引了列表里有没有?那条列表里有但正文到底用没用?顺序编码制下序号有没有因为增删段落而错位?
这件事的学名可以叫「引用核对」。但多数人叫它「改格式前最不想干的那件事」。
关于GB/T 7714-2015,网上能找到大量格式指南:著录项目怎么排列、标点是中文还是英文、文献类型标识[M]和[J]分别对应什么、作者超过三个怎么处理、中英文混排时「等」和「et al.」如何切换。这些内容解决了「写对了没有」的问题,但没有解决另一个更前置的问题:正文每一条引用是否都有可靠的来源与之绑定。
格式正确 ≠ 引用完整
GB/T 7714-2015的两种标注体系(顺序编码制和著者-出版年制)各有各的坑。顺序编码制下,正文引用序号必须与文后列表严格对应,但写作过程中增删段落、调整论述顺序是常态,序号很容易漂移——正文第5处引用实际指向列表第8条,而列表第5条变成了空挂。著者-出版年制规避了序号漂移,却引入了另一类问题:作者名拼写差异(同一作者在不同条目中写法不一致)、同年多篇文献的a/b后缀遗漏。
更隐蔽的是三类结构性错误:正文引用了某篇文献,但参考文献列表里根本没有这一条(引用无来源);参考文献列表里列了某条资料,但正文从未引用(资料未使用);同一篇文献在正文和列表中信息不对应,比如年份不同、作者名写法不同(绑定错配)。
格式检查工具能告诉你逗号是不是英文逗号、斜体有没有漏标。但格式检查工具不会告诉你:你正文第3段引用的「Zhang, 2022」在列表里根本不存在。
手动核对与Zotero各自的盲区
手动逐条比对是最原始也最不可靠的方案。当引用数量超过30条,人脑的注意力衰减会显著增加遗漏概率。更关键的是,手动核对发生在写作完成后——此时发现一条遗漏引用,可能意味着要回溯到几周前标记的某处论点,重新确认来源、补充条目、调整序号链,牵一发动全身。
Zotero和EndNote解决了文献存储和格式化输出的问题,但它们的核心设计目标不是写作过程中的引用状态校验。Zotero的CSL样式可以按GB/T 7714-2015输出参考文献列表,Word插件可以在正文插入引用标记——但这些操作的假设前提是「你插入的每一条引用都正确,且你在写作中不会遗忘或重复使用某条文献」。写作者的实际状态是:写到第三章时已经记不清第一章引用过的某篇文献是否已入库,也不确定新插入的这条引用此前是否以不同的元数据形式存在于库中。Zotero不会主动提示你:这条引用没有对应来源;这条资料你入库了但从没引用过。
三态诊断:给每一条引用一个明确身份
如果把正文引用标记和资料库条目看作两端,它们之间的连接关系只有三种可能状态:
Bound(已绑定):正文中的引用标记明确指向资料库中的某条文献,两边信息一致。这是理想状态,代表「引有所据」。
Orphan(孤立引用):正文中出现了引用标记,但在资料库中找不到对应来源。可能是引用标记写错了别名,也可能是这条文献尚未入库。不管原因如何,结果相同——正文声称有所依据,但依据丢失了。
Dangling(悬空资料):资料库中存在一条文献,但正文从未引用它。可能是这条资料确实不需要引用(比如只是阅读过但未直接使用),也可能是写作者原本计划引用却在写作中遗漏了。
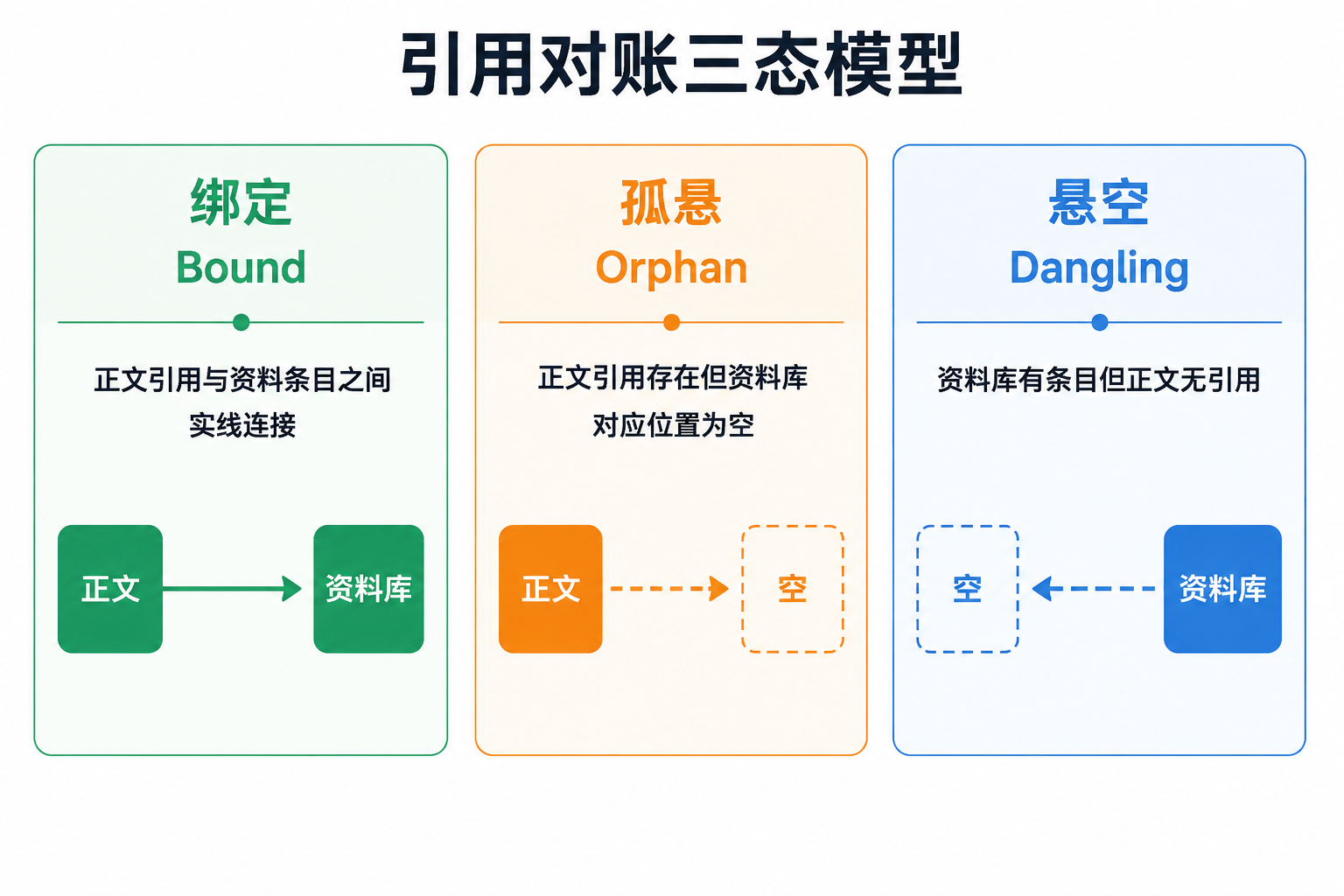
这个分类框架的价值不在术语本身,而在于它把「感觉哪里不对」变成了可逐一排查的清单。看到Orphan,只需要顺着正文引用标记去找缺失的来源;看到Dangling,只需要判断这条资料是废弃还是需要补引用。排查路径是确定的,不需要凭记忆在正文和列表之间反复跳转。
把核对前移到写作过程中
现有方案几乎都把参考文献检查定位为「导出前的工作」:写完全文,生成列表,比对,修改,再生成,再比对。问题在于,当引用核对被推迟到写作终点时,发现的每一个问题都可能要求回到正文中修改,打断的不只是格式流程,还有对论述逻辑的确认成本。
更合理的做法是让引用校验发生在写作的每一刻。InkFount作为研究型写作工作台,采取了「资料层前置」的设计:在Markdown写作界面中,正文通过[@alias]语法与资料库实时绑定,系统持续追踪每一条引用标记与资料库条目之间的连接状态,并在界面中呈现Bound/Orphan/Dangling三态。写作者在撰写段落的同时就能看到引用状态——新增引用如果指向了不存在的资料别名,立即显示为Orphan;入库后尚未引用的资料显示为Dangling,提醒写作者「这条资料你还未使用」。
这相当于把「写完后逐条核对」的集中劳动,拆解为嵌入写作流程的持续校验。写作流不需要中断,判断力不需要在创作和校对之间反复切换。
从核对到交付:GB/T 7714-2015格式化
引用核对确保的是「引得有据」;格式导出解决的是「交得出去」。InkFount支持按GB/T 7714-2015标准导出参考文献,覆盖期刊论文、专著、学位论文、会议论文、专利、电子资源等常见文献类型,自动处理中英文混排时的标点切换、「等」与「et al.」的选择、文献类型标识的标注。
导出只是最后一步。真正降低返工成本的,是把引用绑定关系理顺这一步前置了——格式可以自动生成,但正文与来源之间断掉的连接,任何格式化工具都无法替你接上。
写作主权归你,校验成本归工具
引用核对也好,格式化导出也好,AI辅助改稿也好,最终面向的是同一个问题:研究型长文的写作成本,大量消耗在非创作性劳动上——查格式、对引用、调序号、改措辞。这些劳动必要但不产生新的学术价值。
InkFount的定位是研究型写作工作台而非「一键生成论文」的AI写作器。它的AI改稿基于已有稿件做精确修订(逐段、逐句地改,产出可逐条审阅的diff),引用核对追踪正文与资料库的绑定状态,格式导出覆盖Word/PDF/LaTeX三种交付格式。作者始终是判断的主体——哪条资料该引用、哪处论述该调整、哪种表达更准确——工具负责让这些判断落地得更快、更准,而不是替代判断本身。
「写得可控、引得有据、交得出去」不是口号,而是一个可操作的流程:在Markdown中写作,引用实时核对,AI按需改稿,最后按目标格式交付。GB/T 7714引用核对是这个流程中承上启下的一环——它把参考文献管理从导出前的格式焦虑,变成了写作中的状态确认。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
AI 论文改稿工具怎么选:看 diff、引用、导出,而不是看能不能一键生成
市面上的 AI 论文工具都在强调“一键生成”,但严肃学术写作的核心是改稿。本文把工具分成聊天框、一键生成工具、研究型写作工作台三类,用四个硬标准——diff 可见性、撤回能力、引用对账、可交付导出——帮你穿透营销话术,找到真正能用的改稿工具。
ChatGPT 写论文为什么总编假文献?问题不在模型,在你的写作流程
ChatGPT 生成的参考文献格式完美却查无此文?根源不是模型幻觉,而是聊天框写作让引用与正文脱节。本文从工作流角度给出可落地的解决思路。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。