论文查重的真正防线,不该从定稿后才开始
查重焦虑的根源不在定稿后,而在写作过程中。从引用核对、AI精确改稿到写作主权,拆解一套把风险控制前置的写作方法。

避免论文查重与AIGC检测风险,不应在定稿后才开始——真正有效的防线,是从写作第一句话就建立“来源可追溯、改稿可审阅、格式可交付”的工作习惯。这与其说是一种技术方案,不如说是一次视角的转换:把事后补救的精力,前置到写作过程中的每一处引用、每一次修改、每一次格式确认。
写完论文再回头降重,这件事许多研究生都经历过。把一段话翻来覆去地改,换词、调语序、拆分长句——折腾几天,重复率勉强压下去了,但文章读起来疙疙瘩瘩,导师看了也皱眉。更让人不安的是近两年新增的AIGC检测:重复率过关了,系统却标出一大片“疑似AI生成”,而AI痕迹埋在句式结构、用词分布和段落节奏里,改起来没有明确抓手。
这两类问题的共同点在于:它们不是定稿后才冒出来的,而是在写作过程中一天一天累积起来的。引用了一处观点却忘了标注来源,让AI帮忙扩写了一段却直接贴进正文,从几篇文献里拼凑了一个段落却搞混了出处——这些操作在写作当下看起来微不足道,落到检测报告里就成了需要逐条应对的麻烦。
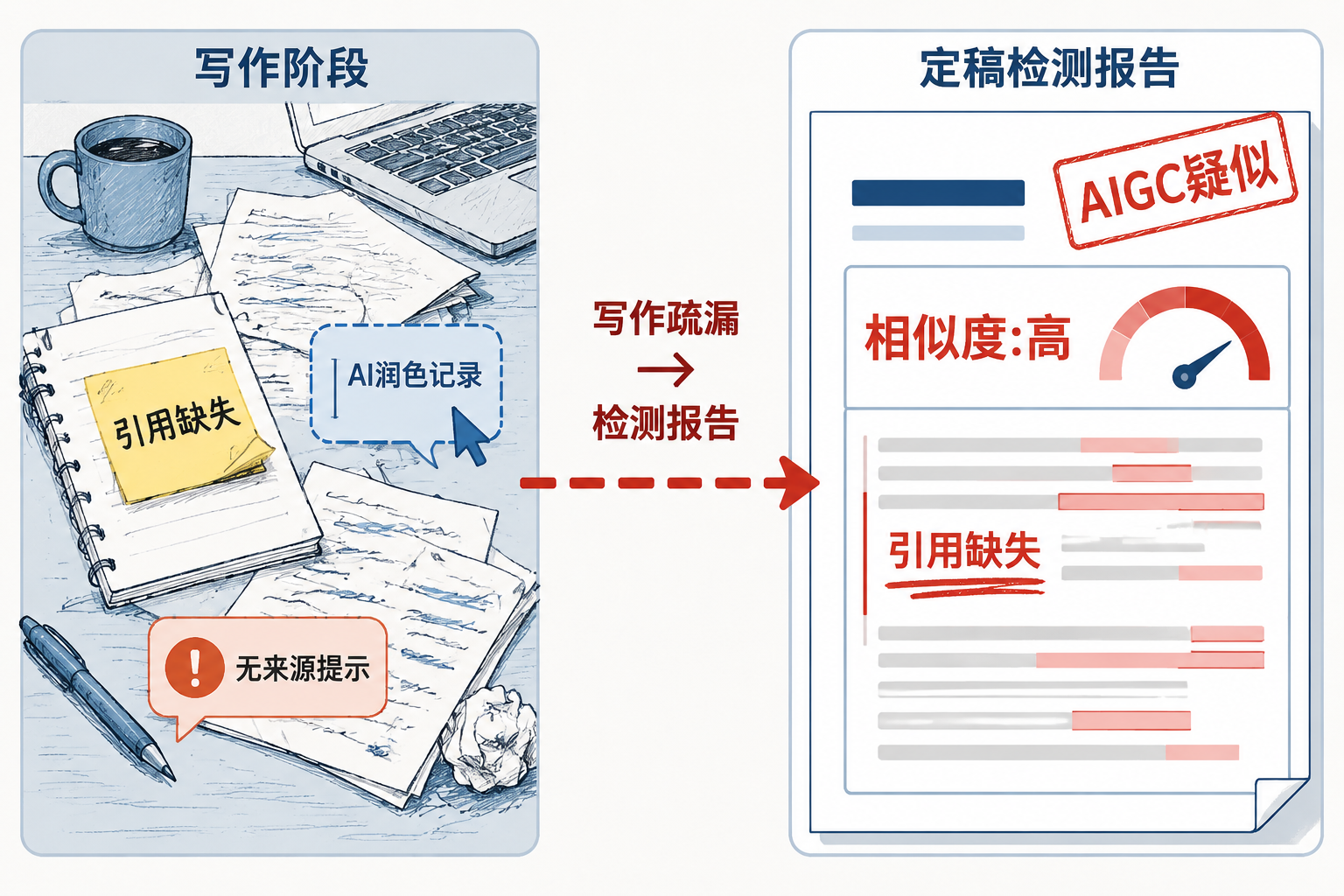
风险不是检测系统制造的,是写作习惯留下的
论文查重系统做的是文本相似度比对——把你的句子和数据库里的文献做匹配,标出重复片段。AIGC检测则分析文本的“生成特征”:词汇分布是否过于均匀、句式复杂度是否异常规律、是否存在模型偏好的高频搭配。两者技术路径不同,但审视的对象是同一个东西:你交给系统的那份终稿。
问题在于,终稿里的风险,在写作阶段已经产生:
引用无来源(orphan citation)。 正文里写了“研究表明”“有学者指出”,参考文献列表里列了若干条目,但具体哪句话对应哪条文献,只有模糊的印象。这种脱节在写作时察觉不到,导出时也未必出错——参考文献列表格式完整、数量合规——但检测系统逐句比对时,大量“来源不明”的论述会被归入可疑区间。
AI生成残留。 让AI写了一段文献综述或理论框架,大致看了一眼觉得“差不多”,就放进了稿件。这段文本本身可能不重复,但它的语言模式——均匀的句长、高比例的连接词、低频词缺失——在AIGC检测器看来异常醒目。更关键的是,这种全量生成的文本没有修改链路可追溯:你不知道哪些措辞是模型选的,也不知道它在哪个判断上替你做主了。
拼凑式写作造成的来源混乱。 从三五篇文献中各取一段,用自己的话串起来,但过程中没有同步记录每句话对应的出处。写完回头补充引用时,已经分不清哪句来自哪篇。最终的结果是:要么引用标错位置,要么干脆漏标——前者在查重中表现为“引用异常”,后者直接构成抄袭风险。
这些问题的根源不在检测环节,而在写作环节缺乏一个机制:让正文里的每一处引用,都有一个可以追溯的锚点。
![示意图:正文中的[@张三_2024]标记通过点状箭头连接到侧边栏资料卡片,卡片显示标题、作者、年份和关键摘要字段标签及占位符。](image-02.webp)
引用核对:在写作中完成,而不是导出前补救
打个比方:财务记账有两种做法。一种是日常随手记,年底把发票翻出来逐条核对,发现少了三张、对不上五笔;另一种是每发生一笔就即时入账、勾稽凭证,到出报表时账目自然是一平的。引用管理也面临同样的选择——多数人的做法是前者:正文埋头写,引用标记随手加(或者不加),排版时再统一整理参考文献列表。
引用核对的思路是后者:正文中的每一个引用标记,从它被写下的那一刻起,就与资料库中的某一条记录绑定。系统持续跟踪三种状态——
- Bound(已绑定): 正文中的标记在资料库里有对应条目,且该条目确实被正文引用。账实相符,无需额外处理。
- Orphan(孤立引用): 正文中出现了引用标记,但资料库里找不到对应的来源。好比发票找不到了——要么补录这条文献,要么标记待确认。
- Dangling(悬空资料): 资料库里有条目,但正文中没有任何一处引用它。可能是预备阅读但未使用的文献,也可能是你写了某段话却忘了标注引用——后一种情况就是潜在风险。
这三种状态不是导出时的一次性检查,而是写作过程中随时可见的。当你写到一个段落、插入一个引用标记时,系统立即告知这个标记的状态。如果标记是orphan,你不会等到定稿才发现“这篇文献在哪来着”——问题就在你写那句话的同时被暴露出来。
这改变了一个根深蒂固的习惯:参考文献不再是正文写完后的一块附录工作,而是写作本身的一部分。当资料层前置到写作过程中,正文和文献列表之间的脱节自然消失。
AI改稿与AI生成,在检测面前是两回事
一个容易被忽视的差别:AIGC检测器对“AI整段生成”和“AI局部修改”的敏感度不同。整段生成的文本通常具备更完整的AI语言特征——句式均匀、过渡平滑、信息密度偏低——而围绕已有稿件进行的精确修改,保留了原文的结构骨架和个人措辞习惯,AI的参与更接近语法修正和逻辑衔接优化。
这里的关键不是“用了多少AI”,而是“AI以什么方式参与”。如果每次AI介入产出的是一条可审阅的diff——哪些行被删除、哪些行被新增、哪些行被替换——你就可以在采纳之前逐条判断:这个修改是否保留了原意?措辞是否符合你的表达习惯?改动范围是否超出了必要?

这种工作方式把AI从“替作者写”变成了“帮作者改”。你始终是每句话是否保留、每处修改是否接受的判断者。AI不替你决定论点走向、不替你选择引用哪篇文献、不替你判断数据该如何解读——这些决策权留在你手里,AI只负责降低执行这些决策时的机械成本:改措辞、调结构、统一术语。
从AIGC检测的角度看,这种写作模式下产出的文本,其语言特征更接近人的写作过程——有不均匀的句式分布,有个人的用词偏好,有修改迭代的痕迹。而这些特征,恰恰是整段AI生成文本所不具备的。这也是“写作主权”在技术层面的含义:不是拒绝AI,而是让AI在你可以审阅、可以撤销的框架内工作,最终成稿的语言指纹仍然属于你。
一套链路走到底,减少转换中的格式损耗
写作过程中的另一类隐性风险来自格式转换。在Markdown里写完正文,导出到Word排版时参考文献格式乱了;公式用第三方插件渲染,换到学校模板里显示异常;图片题注在多次转换后编号错位。这些问题本身不直接触发查重,但格式混乱会导致参考文献标注不匹配、引文信息丢失,间接引发检测异常。
理想的情况是:从写作到交付,在同一环境中完成。正文用Markdown书写以保证结构清晰、修改可控;参考文献在写作过程中已与正文标记绑定,导出时按GB/T 7714-2015自动格式化;公式就地渲染,图片与题注一一对应;最终一键导出Word或PDF,格式与写作时保持一致。省去的不仅是来回转换的麻烦,更是转换过程中可能引入的引用错配。
多模型选择本身就是一种风险分散
不同的大语言模型在中文表达、学术语境适配、生成文本的特征上差异明显。有些模型输出的中文更书面化、句式更工整,在AIGC检测器看来反而更“像AI”;有些模型的中文表达更接近自然写作的节奏,但可能在专业术语使用上不够精准。
没有哪个模型在“降低AIGC痕迹”这件事上绝对优于其他——因为检测算法也在不断更新,对不同模型的敏感度随时间变化。真正有效的策略是保留选择空间:根据具体任务(综述润色、方法描述、讨论修改)选择当下的模型,避免长期依赖单一模型的固定语言模式在稿件中形成可被检测的稳定指纹。
与此同时,选择权也体现在成本和可用性上——不必因为某个服务的网络不稳定或额度耗尽而中断写作,切换模型即可继续工作。这种灵活性对于写作周期通常持续数周甚至数月的研究型长文来说,不是锦上添花,而是稳定产出的基本保障。
把学术诚信从检测焦虑还原为写作纪律
回到开头那句话:真正有效的防线,是从写作第一句话就建立“来源可追溯、改稿可审阅、格式可交付”的工作习惯。查重焦虑的根源,是把本应贯穿写作全程的规范行为压缩成定稿后的一次性技术应对。
前置型风险控制不是某种工具独有的功能,而是一种写作范式:
- 每一处引用在写下时就知道它指向哪里——不是靠记忆力,而是靠正文标记与资料库的实时绑定。
- 每一次AI修改都产出可逐条审阅、可撤销的变动记录——AI不替你写作,你始终是每句话去留的判断者。
- 每一版稿件都能直接交付为符合规范的终稿——格式一致性不是导出后手动检查的结果,而是写作环境的内置能力。
这三条把写作主权落到了具体动作上。当你不再需要为查重和AIGC检测焦虑,不是因为数值被人为压低,而是因为风险从未在写作过程中被埋下。学术诚信从“检测能不能过”的外部压力,回归为“我写的每一句都有据可查”的内在纪律——这才是长期可持续的学术写作方式。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
学术论文图表格式规范全解:表题、图题与数据来源标注的正确方法
图表格式不规范是论文被退回的高频原因。本文系统讲解表题与图题的位置和编号规则、三线表规范、数据来源的三种标注方法,并从写作流程角度分析如何避免图表返工。
论文引用核对清单:用 bound / orphan / dangling 三态法逐项检查,交稿不返工
一份可直接执行的引用核对清单,掌握 bound / orphan / dangling 三态校验,确保正文引用与参考文献一一对应,符合 GB/T 7714-2015,降低交稿返工风险。
学术论文摘要怎么写?GB/T 6447-2025 新国标下的结构、字数与关键词策略
基于2026年实施的GB/T 6447-2025《文献摘要编写规则》,系统讲解学术论文摘要的结构(目的-方法-结果-结论)、字数规范与关键词选取策略,帮助研究者写出符合期刊要求且检索友好的摘要。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。