AI 生成的参考文献靠谱吗?从 DOI、BibTeX 到正文引用的完整校验链路
Nature 最新分析显示,2025 年超过 14 万条虚假引用出现在学术论文中,其中大量由 AI 幻觉产生。本文提供从 DOI/BibTeX 校验、正文引用绑定到段落支撑验证的四步链路,帮助学术写作者把参考文献从「看起来像真的」变成「能查、能对、能交付」。

2026 年 5 月,Nature 披露了学术出版中一个严峻趋势:2025 年全年,仅四个主要研究仓储的论文和预印本中就被检测出超过 14 万条虚假引用,大量由 AI 幻觉产生。面对这一系统性风险,保障参考文献可靠性不能依赖导出前的逐条抽查;真正有效的做法,是将校验嵌入写作流程,从 DOI/BibTeX 源头核实、正文引用绑定、到段落支撑验证和格式终审,形成一条「能查、能对、能交付」的完整闭环。本文即分四步拆解这一闭环。
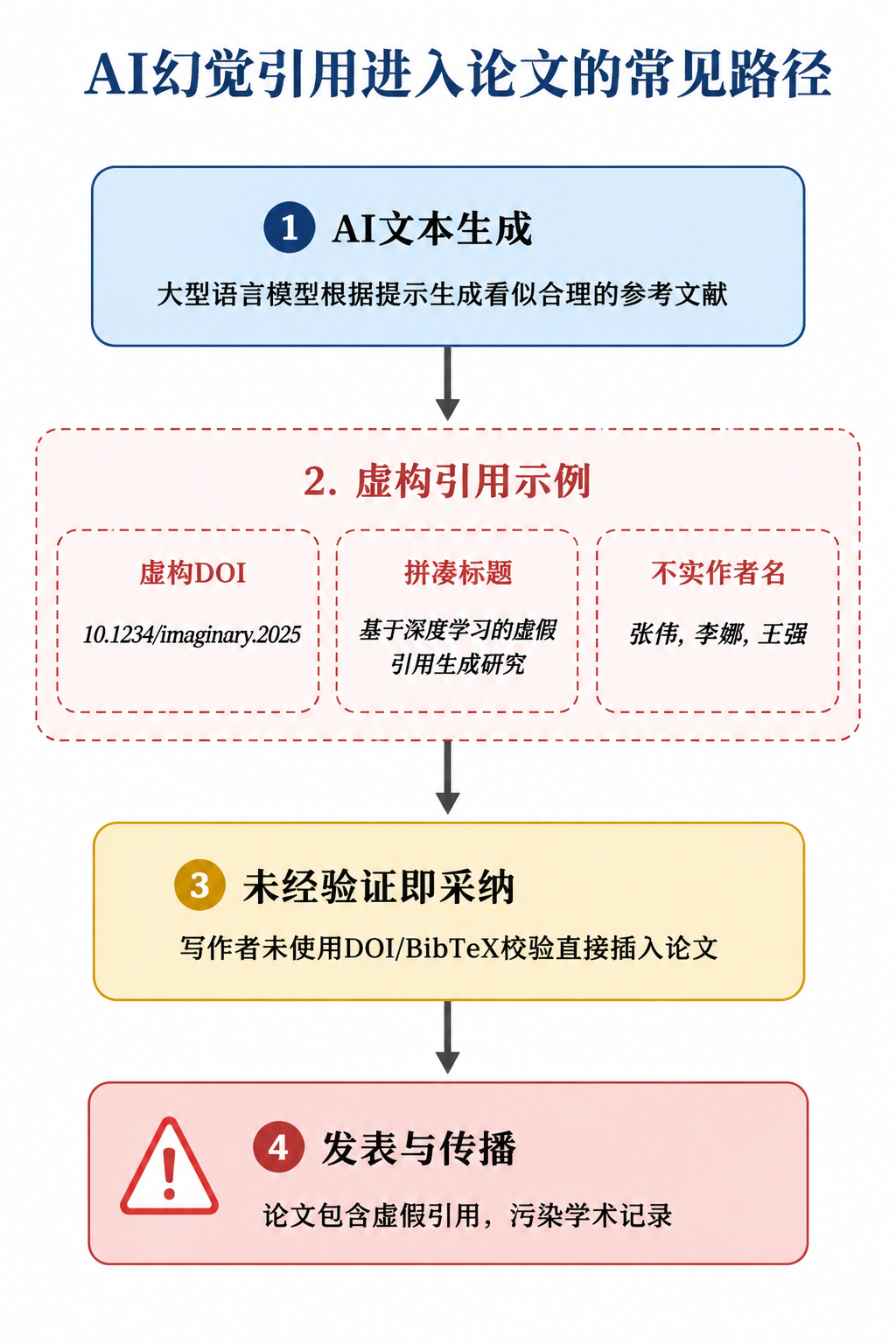
第一步:DOI 和 BibTeX 是真是假?源头校验方法
拿到一个看起来完整的 DOI(如 10.1234/example.2025.001),第一件事不是直接导入参考文献管理器,而是验证其真实性。最直接的方式是在浏览器中打开 https://doi.org/DOI号,若跳转至具体的期刊页面且信息匹配,初步可信。更严格的做法是调用 CrossRef API:通过命令行输入 curl https://api.crossref.org/works/DOI号,返回的 JSON 数据包含标题、作者、出版年份、期刊名称等字段。将这些字段与 AI 生成的条目逐项比对,虚构的 DOI 会返回“Resource not found”,或虽有返回但字段与声称的不符。
对于 BibTeX,许多 AI 模型会生成格式正确的条目,但其中的卷、期、页码可能拼凑而成。验证方法同样是提取其中的 DOI,或从标题字段反向搜索。在 Google Scholar、Semantic Scholar 或对应数据库中检索标题,能快速确认文献是否真实存在。对于中文文献,还需核对 CNKI 或万方数据库中的记录。这一步虽耗时,却是整个校验链的基石。
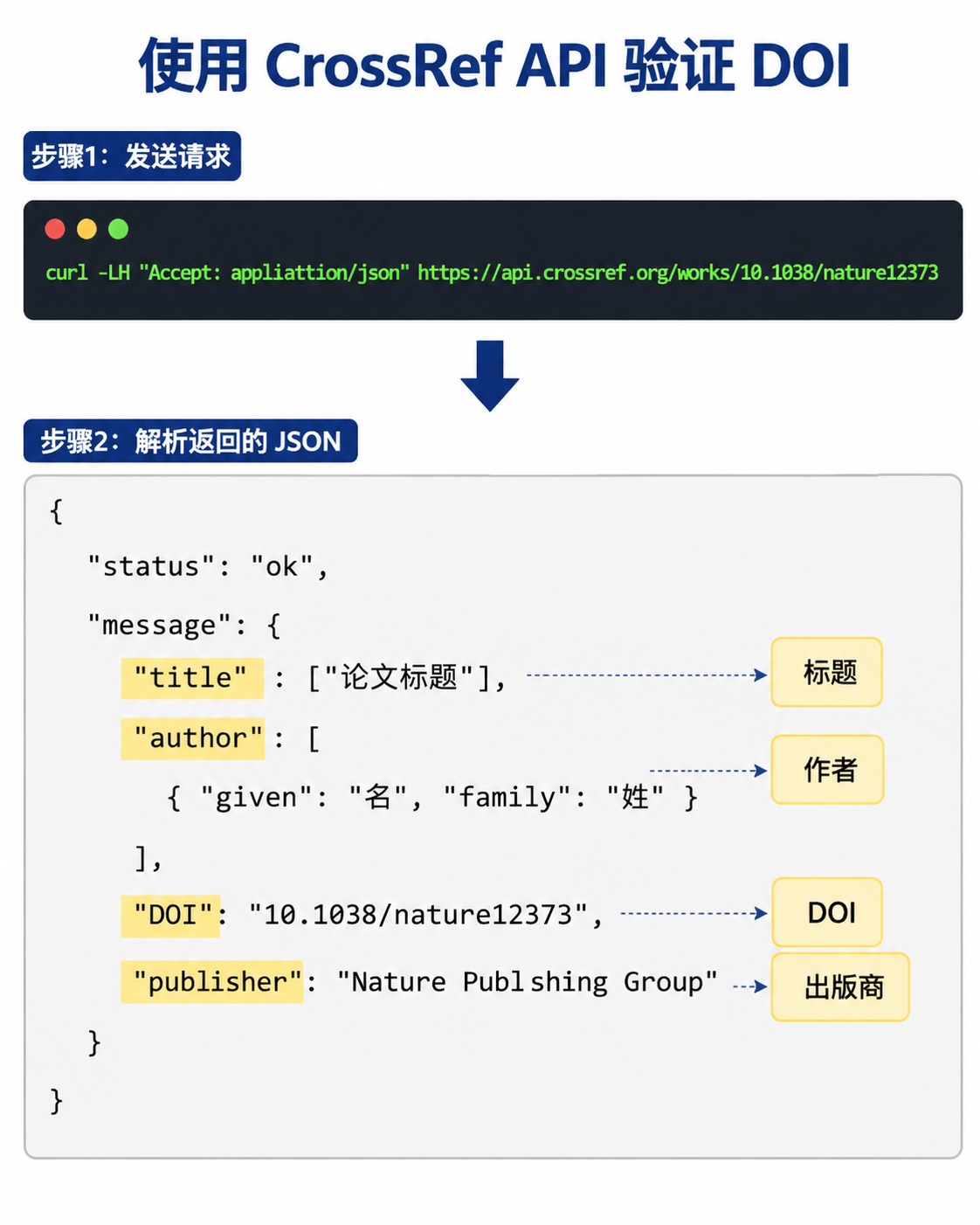
需要留意的是,这一校验不应只在导入文献库时做一次。在写作过程中,随着引用增减,仍需保持源头数据的准确。更高效的方式是将文献信息以结构化形式(如 BibTeX 或 CSL JSON)存入写作工具的资料层,使后续步骤直接基于已核验的条目,而不是从正文注释中临时提取。
第二步:正文引用与文献库绑定,消除「幽灵引用」
许多论文出现引用错误,并非因为文献本身虚假,而是正文中的引用标记与最终参考文献列表脱节。例如,正文中标注了“[5]”,但参考文献列表中条目序号缺失或重复;又或者,正文中引用了一个作者-年份组合,而文献库中没有对应条目。这两种情况可分别称为“幽灵引用”(正文引用了但文献库无对应条目)和“悬空引用”(文献库中有条目但正文从未提及)。这两类问题在传统写作方式下,往往直到排版阶段才暴露,修正成本极高。
解决之道是将正文引用与文献库条目的绑定关系显性化。在 Markdown 写作中,可以使用类似 [@smith2025] 的标识符,代表对某个已录入文献条目的引用。写作工具若能识别这种语法,就能实时追踪每个引用标识符是否对应文献库中的条目(bound)、是否有标识符找不到对应条目(orphan,幽灵引用),以及是否有条目未被任何正文引用(dangling,悬空引用)。
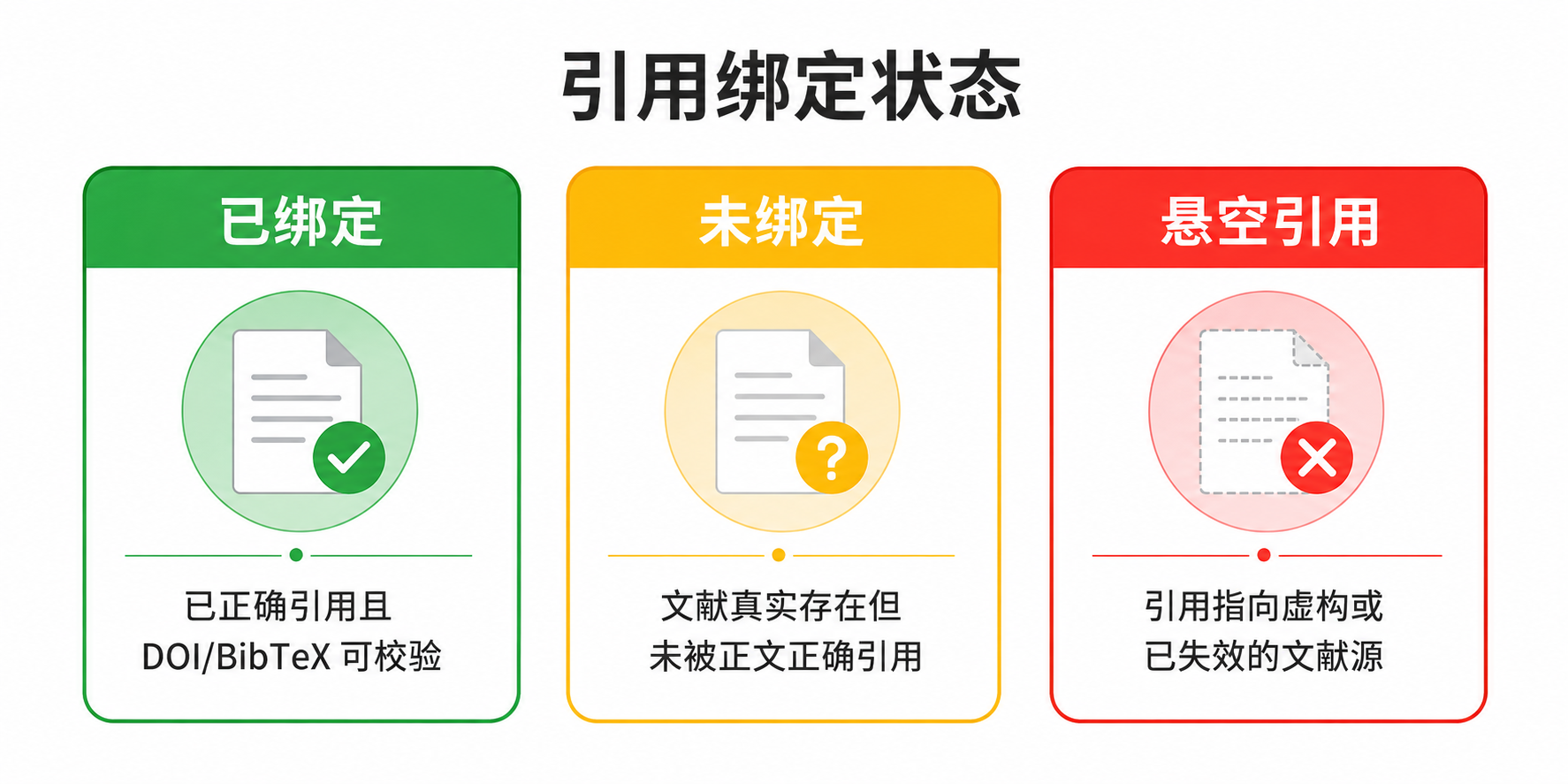
这一步将引用对账从“事后排查”变成“边写边对”。每当插入一条引用,若标识符未在文献库中定义,工具即刻提示;若某条目在后续删改中不再被引用,也能被清晰标记以供清理。这种机制确保了正文与文献列表的同步性,为第三步的内容级验证打下基础。
第三步:这篇文献真的支撑当前段落吗?内容级验证
即使文献真实存在且绑定正确,引用的方式也可能不合理。学术写作中常见的误区包括:引用一篇论文来支持某个观点,但该论文实际上并未得出相应结论(“张冠李戴”),或者只截取摘要的部分语句而忽略研究的限定条件(断章取义)。在 AI 辅助生成文本时,由于模型并不真正理解文献内容,这类错配的出现概率更高。
内容级验证要求写作者对每一处关键引用进行两项检查:第一,所引文献的研究问题、方法和主要发现是否与正文论点匹配;第二,引用的上下文是否准确反映了原文的结论与适用范围。这通常需要查阅文献的摘要、引言和结论部分,有时还需快速浏览图表与数据。为提高效率,写作者可以尝试将当前段落与所引文献的摘要一同放入写作工具的 AI 辅助区,让 AI 基于给定文本快速指出哪篇文献直接支撑观点、哪篇仅部分相关,从而靶向调整。若工具支持绑定文献库,还可直接调取已核验的摘要,无需反复跨窗口复制。当然,AI 的辅助判断只能作为参考,最终责任仍在写作者。通过这一步,参考文献从“形式上不缺”进阶到“实质上支撑”。
第四步:导出前的最后一关——参考文献列表格式化与终审
即便前三步都已完成,参考文献列表中仍可能因格式转换而出现错误。中文论文通常要求符合 GB/T 7714-2015 标准,它细致规定了各类文献的著录格式:例如,期刊论文需依次列出作者、题名、刊名、出版年份、卷号(期号)、页码;会议论文则需注明会议名称、地点、日期等。AI 或文献管理工具在自动生成格式化列表时,可能因数据源自身的瑕疵(如作者姓名字段分割错误)导致格式偏差。
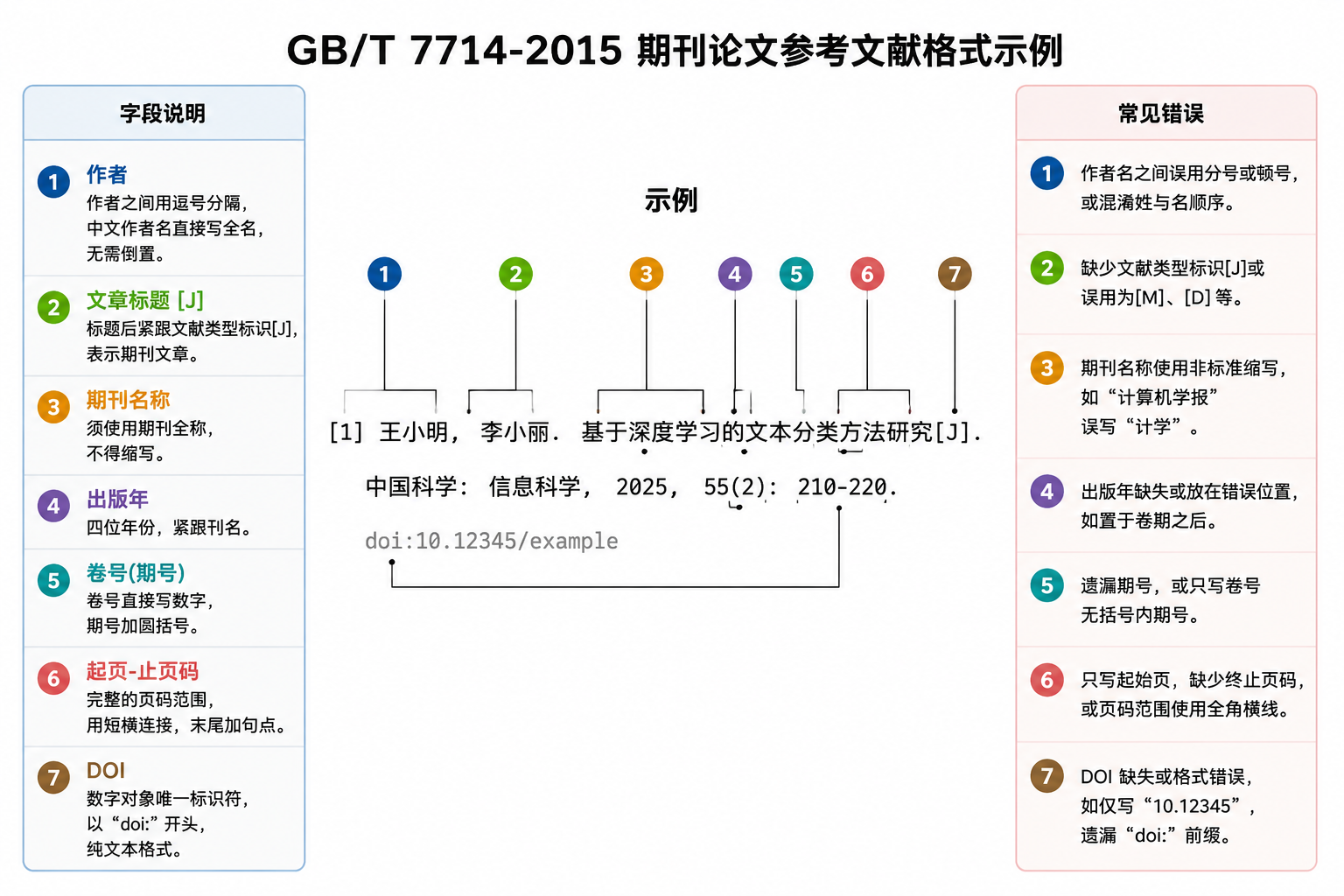
导出的 PDF 或 Word 稿件交付前,建议进行一次“终审式”核对:逐条检查参考文献列表中每一项的作者名(大小写、缩写一致)、标题(标点、大小写)、刊名或出版社、出版年、卷期页码是否与经过验证的原文一致。重点核对被引频次较高或核心论据的文献。同时,再次确认正文中的引用标记与列表完全对应,没有移位或遗漏。这一步看似繁琐,却是学术严谨性的最后防线。正因为前面已将文献库绑定和内容核实分开处理,此时的核对压力已大大减轻——重点只在于格式表象。
从「看起来像真的」到「能查、能对、能交付」:工具如何帮你落地
上述四步形成一个自洽的校验闭环,但若每步依赖不同的工具或平台,窗口切换和重复校对反而可能增加出错风险。以 InkFount(paper.InkFount.com)这类一体化学术写作工作台为例,可以看到设计如何将校验嵌入写作流程本身。
首先,InkFount 在资料层前置文献管理。用户可以在写作开始前,通过 DOI 或 BibTeX 导入文献,工具内部会自动尝试调用 Crossref 等接口进行基本验证,并将结构化数据存入资料库。这为后续所有引用提供了单一可信源,避免了从聊天框中临时复制文献条目。
其次,正文引用绑定采用 [@alias] 语法。当用户在 Markdown 中插入 [@smith2025] 时,工具实时检查资料库中是否存在该别名对应的条目,并将引用状态标注为 bound、orphan 或 dangling。引用对账面板在整个写作过程中持续可见,写作者可以随时修正,而不是等到最后才面对一团乱麻。
第三,InkFount 的 AI 改稿功能围绕当前文稿的上下文工作,而非在隔离的聊天界面中。当需要对某段落的引用支撑度进行评估时,可以选中文本并请求 AI 参考已绑定的文献内容给出建议。这使得第三步的内容级验证不再是脱离写作流的额外工序,而成为写作的自然延伸。
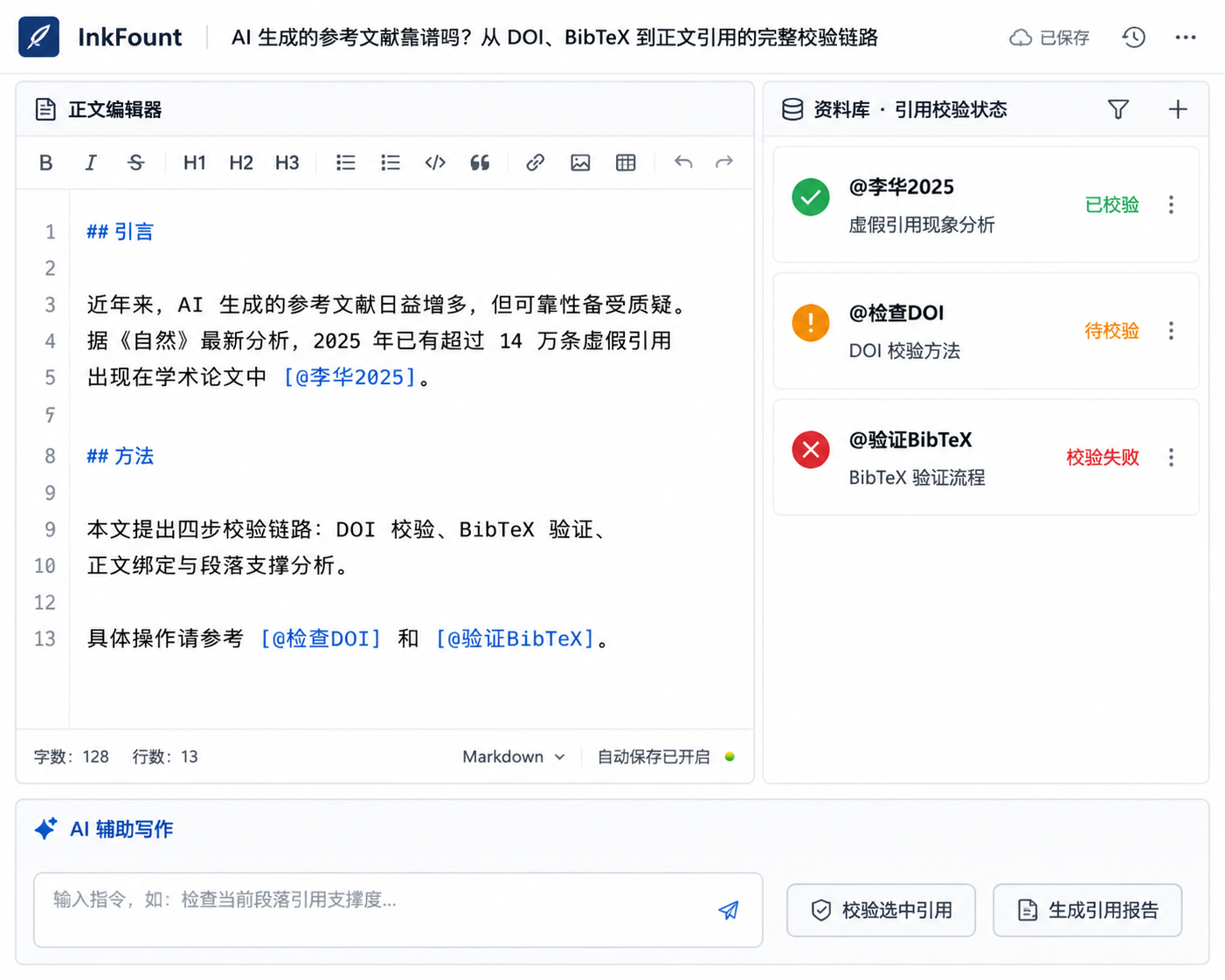
一体化工作台无法杜绝幻觉,但它把耗时的校验步骤拆解并持续地融入写作过程,让“事后抽查”的旧模式转变为“过程可控”的新模式。当参考文献的每一重信息——从 DOI 真伪到段落归因——都在同一环境中被有序管理时,“看起来像真的”才真正走向“能查、能对、能交付”。
继续阅读
这些相关文章可以帮助你补齐写作流程中的其他环节。
参考文献和正文引用对不上怎么办?一套交稿前检查流程
论文定稿前发现参考文献与正文引用对不上?本文提供一套三步检查流程:从正文引用标记查起,反查文献表,最后校验导出文档,并介绍 InkFount 如何把引用核对前置到写作现场,避免事后补救。
AI 论文改稿工具怎么选:看 diff、引用、导出,而不是看能不能一键生成
市面上的 AI 论文工具都在强调“一键生成”,但严肃学术写作的核心是改稿。本文把工具分成聊天框、一键生成工具、研究型写作工作台三类,用四个硬标准——diff 可见性、撤回能力、引用对账、可交付导出——帮你穿透营销话术,找到真正能用的改稿工具。
ChatGPT 写论文为什么总编假文献?问题不在模型,在你的写作流程
ChatGPT 生成的参考文献格式完美却查无此文?根源不是模型幻觉,而是聊天框写作让引用与正文脱节。本文从工作流角度给出可落地的解决思路。
在 InkFount 中实践这套方法
你可以直接在编辑器里搭建提纲、管理参考文献、插入引用,并在导出前完成结构与格式检查。